

Crafting an end-to-end Data Pipeline – Ingest, Transform, and Store
Overview
Data is messy, scattered, and oftentimes unusable in its source form. Piecing together data from different resources and manipulating it in a way that can benefit your business was once a manual, time consuming process. For financial services organizations, much their data is stored in on-premises environments. With the vast number of systems and software tools in use by these organizations, data sources for a single business function are siloed. To perform any sort of analysis on the data, an analyst would have to extract data from multiple sources and logically combine it, oftentimes using manual mapping and cleansing methods. Due to the manual nature of this process, repetition does not guarantee similar analytical results, which results in reporting discrepancies.
Building a system to solve the problem of consolidating data in a way that can be easily consumed by downstream applications are typically complex. An on-premises solution brings in complications of managing and scaling resources that can handle the exponentially growing amounts of data our clients face. Over time, these solutions prove to be unsustainable, not just from a resource perspective, but also operationally.
In this solution, we will utilize the concept of a data pipeline to eliminate inconveniences that come with the vast amount of data financial services companies have. A data pipeline is an automated series of steps in which our data is ingested, transformed, and stored. By utilizing cloud-native services within AWS, we will be able to build a solution that scales as your data and business needs grow.
Below are some of the key benefits of cloud-native data pipelines:
- Saves time by automating data pipeline ETL (extract, transform, load) processes
- Reduces number of potential errors that occur in manual data processing
- Quicker access to new data for business decision making
- Fine-grained control over security of the pipeline and data in the pipeline
- Simplicity in scaling resources as data quantities increase
- Reduces operational overhead by leveraging managed services throughout the pipeline
Prescriptive Guidance
Before diving into the Pipeline Foundations, it is important to acknowledge that depending on the use case of the data pipeline, and the data itself that is to be processed, the complexity of the solution will vary. There are also many conceptual considerations to think about before creating a data pipeline, which are specified below. This foundation provides a blueprint for data ingestion from common sources, transformation strategies, storage solutions, and metadata management guidance, all while keeping automation, scalability, and security in mind.
Definitions
- Data Pipeline – An automated series of steps in which our data is ingested, transformed, and stored for end user consumption
- Source Systems – Location (file storage system, object storage, database, etc.) where the data is coming from
- Target Systems – Destination where the data is being moved to
- Extract, Transform, Load (ETL) Processes – The process of taking data from the source system, performing data transformations (cleansing, standardizations, deduplication), and loading it into the target system
- Relational Data – Data that is structured (typically a database) with defined relationships between the data elements
- Streaming Data – Data that is being continuously generated by a source
- Flat Files – Typically stored in a .csv or .txt format, a flat file is a table of data with rows containing records
Best Practices
Determining a Use Case
Large organizations will typically have hundreds of sources producing data and a variety of end-user data consumption needs. It is necessary to build out data pipelines in a way that makes sense not only from an engineering perspective, but also from a business and operational perspective. In the cloud, there are limitless options. We provide a general direction to navigate the right approach the in any cloud journey. We seek to understand your data process, and to improve it, by providing scalable methods for growth.
- Complete a Thorough Analysis of Existing Source Systems:
- Identifying what data will need to be available for consumption at the end of the pipeline.
- Understanding current data relationships will help improve the organization of the data at the end of the pipeline.
- Assess How Data is Generated and Used – Review any existing data processes that are manual to identify areas that can be automated with a data pipeline.
- Determine an Approach to Data Management – Set holistic processes and guidelines for how your data is to be handled and shared throughout your organization.
- Understand your Data and Produce Business Value – Understand what data you have, and data that could potentially have value in the future to gain insight on your business.
Completing these key activities will help identify areas to improve data quality and architect a pipeline solution to address their business problems. Ultimately, the goal is to process data quickly and efficiently to derive value and maximize profitability.
Moving Towards Data Consolidation
Financial Institutions often store their data in departmental silos, creating inconsistencies in their enterprise data. Proper data management efforts are needed to create a golden source of data that is in sync across all platforms to prevent compliance breaches and operational inefficiencies. Oftentimes, different departments require the same sets of data for various purposes. Depending on the use case and business requirements, we recommend designing your pipelines to maximize efficiency by consolidating data and processes where applicable. This will ultimately lead to ease of managing governance when granting access to your data, as well as the security of your pipeline.
Data Security
Financial Institutions are subject to some of the most intense cyber security regulations and requirements, and it is important to keep those in mind when working with your data. Whenever data is being moved, processed, or stored, it is at risk of mismanagement. By building a cloud-based pipeline solution there are many tools at your disposal to protect your data to stay in compliance. Vertical Relevance encourages its clients to use built-in features within AWS to encrypt data at rest, as well as in transit. In addition, during the pipeline stages, services will require access to your data. By enforcing the principle of least privilege within IAM while providing access to services, we can ensure that only the bare minimum is granted to fulfill each task. For more details, please refer to Vertical Relevance’s Data Protection Foundation.
Another important aspect to data security is data identification and classification. Properly identifying and classifying your data makes it easier for you to know what types of data your organization holds (confidential, public, etc.) as well as risk levels of your data (low, medium, or high). We recommend creating consistent resource tagging strategies that identifies and clearly tags the sensitivity-level of data for visibility. For more information on implementing automated data identification and classification within your data pipeline and AWS environment, please refer to our Data Identification and Classification Foundation.
Workflow Automation
The workflow and dependencies of your data pipeline will be heavily influenced by the organization’s business use case. A major driver for creating data pipelines is the ability to eliminate manual tasks that traditional data processing techniques require. To accomplish this, we recommend using pipelines to automate every step of the ETL process from ingestion to transformations. Some areas that we recommend addressing via automation in the data pipeline are the following:
- Automated Ingestion – Data is automatically extracted from source systems and consolidated for processing
- Automated Transformations – Data is transformed as it is generated or on a pre-determined schedule so that it is readily available for consumption
This ability to streamline processes into a step-by-step automated workflow is not only time saving, but also cost efficient.
Scalability – Building Future-Proof Pipelines
An important consideration to take when building out your pipeline is to assess the volumes of data you are working with, as well as estimating a trajectory for how much the data in the pipeline will grow over time. This will affect how you provision your resources and what ETL processing tools to use. This also ties into monitoring and logging the activities of your data pipeline (more info below). We can monitor resource allocation to see if there are any bottlenecks in the pipeline and adjust it accordingly, as well as enable automatic scaling where available to prevent such bottlenecks happening in the first place.
Metadata Management
Metadata refers to data that provides information about your data. There are different types of metadata:
- Technical Metadata – Technical metadata includes the structure of your data (structured, unstructured, semi-structured), data types (int, characters, etc.), length of data, and more.
- Business Metadata – Business metadata refers to the meaning of your data in the context of your business. For example if you have a table containing customer order information, and a column called “total sale” containing a dollar amount, questions might arise around how that amount is calculated (for example, how do we know if the amount includes tax?). The business definition would provide such information.
Oftentimes when building data solutions, the focus of the project revolves around the data itself, so organizations overlook metadata management. However, establishing procedures to manage your metadata is of high importance. Doing so helps maintain data integrity as well as provide context as to what your data means. Creating a data dictionary (a repository that holds data definitions and attributes) is a good first step towards metadata management. While there is no automated technical process to create a data dictionary, it will provide value for both the end-users consuming the data and engineers managing it.
There are other concepts within metadata management to think about as well. A schema is a blueprint of how your data is organized within your database. Creating the schema for a database will be heavily influenced by the business requirements, but there are some technical considerations as well. For example, we want to ensure that the formatting of our schema (in the case of a relational schema, things like table names) is consistent. The schema is also where we define relationships in the data. Ensuring that the schema is accurately created and documented will contribute to the integrity of your data.
We advise our customers to create a metadata management strategy, and an easy way to get started is to incorporate metadata management during the process of crafting your data pipeline. By creating a metadata management strategy, we can prevent our data lake from turning into a data swamp (data stored without organization, and incomplete metadata).
Data Lifecycle Management
Data Lifecycle Management refers to the rules created to manage to store, archive, and delete your data. For data that is in use, it is important to store it in a manner where you can easily have access (managed by a governance process) if needed. If there is data that is infrequently used, a data archive can prove to be an efficient and cost-effective manner of storing your data. Any data that is not used at all, is not legally required to be retained and provides no value should be deleted.
In the context of financial services, there are many laws and regulations about how long certain types of data is to be retained. For example, under the Bank Secrecy Act, banks are required to keep records of accounts for at least five years. When creating lifecycle management rules, it is important to know what data you are working with so that you can set up the rules in a way that is compliant.
While setting up lifecycle rules is dependent on the data and business requirements, a data pipeline within AWS provides many automated functionalities for lifecycle management. The data is automatically archived or deleted based on the rules provided. This eliminates any manual intervention and reduces the risk of error when archiving and deleting data.
Monitoring
VR recommends enabling logging capabilities to monitor the services and workflows that are part of the data pipeline. In event of a failure, the logs will be key to remedying any issues and will contribute to the speed in which your systems can recover from unexpected problems. For example, in the event of an ETL job error, we can trace the issue through the logs and backtrack to find out what data still needs to be processed. The logs provide a starting point to resume to normal operations. Common errors that can occur in a pipeline are:
- Ingestion errors – If our ingestion sources require credentials (such as database credentials) those can expire and cause access errors.
- ETL job errors – ETL jobs can fail for a variety of reasons such as: permission errors or under-provisioning of resources
Solution Architecture Overview
A common use case for creating a data pipeline is to consolidate data from multiple source systems into one master database. Financial Institutions use many services and applications that utilize a backend database. For example, we can have a database containing customer demographic information. Sources of streaming data are also common, and in the pipeline example we have a data stream containing information on customer payments. If we wanted to create an analytical report to see customer payments by demographic, we need to ingest and combine both of those source systems.
In addition, if services pertaining to a related business function (for example transaction processing for each order) is outsourced to another company, the data around that is typically delivered through flat files. Now if we wanted to create analytics around customer payments but also incorporate information regarding transaction processing, we need to combine information from all three source systems.
Let’s consider this business problem to be our base for creating the pipeline architecture and working through the stages of ingesting, transforming, and storing the data.
Components
- Amazon Kinesis –Ingests data in real time from our sample data stream, processes data partitions through firehose, and delivers the data to the raw zone bucket
- AWS DataSync – Connects to our flat file storage and copies the contents to the raw zone bucket
- Amazon Glue – Applies transformation logic to our data including join operations, filters, and schema mapping, and delivers the data to our specified destination
- AWS Step Functions – Orders our glue job workflow in a logical manner to process the data step-by-step
- Amazon Eventbridge – Creates a trigger to automatically kick off our glue job workflow on a schedule that we specify
- AWS IAM – Grants permissions to our services to access other services and data
- Amazon Key Management Service (KMS) – Encrypts our data at rest and in transit
- AWS Database Migration Service – Migration tool used to replicate data from our on-premises database to our raw zone bucket
- AWS Secrets Manager – Stores database credentials for Database Migration Service to access our on premises database
How it works
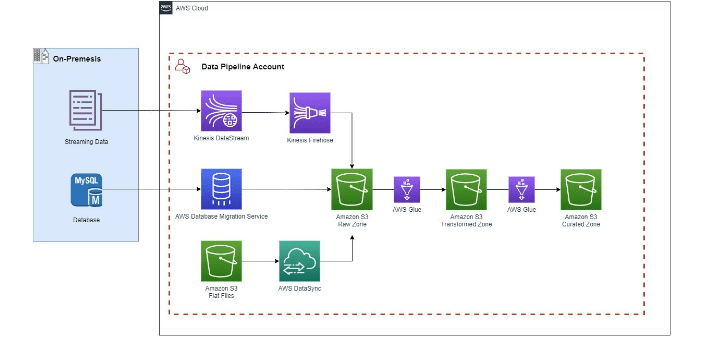
Figure-01
- Determine the Data Models: Before we begin the major components of the solution, we need to come up with a schema of what our master database will look like so that we know what we need to process from our source systems and have a blueprint for what the data will look like during the transformation stage. This depends on the business requirements. There are many data modeling tools that can assist with creating the schema diagram.
- Ingest Data: Data is ingested in real-time from a streaming data source with Amazon Kinesis. Data is also ingested from a MySQL database using AWS Database Migration Service. Flat Files are ingested by establishing a connection with our S3 data store and creating a transfer task with AWS DataSync. All data lands in the raw zone bucket.
- Transform Data: In the first glue job from the raw zone to transformed zone, data will be joined and the mapping will be applied to the new data model. Here is where most of the data cleansing logic will occur. The second glue job from the transformed to curated bucket will contain logic to further curate the data to our consumers.
- Establish Workflow: A workflow will be established to automatically kick off our glue jobs in the logical pipeline order.
Blueprint
This playbook provides guidance on how to build a data pipeline within AWS including ingestion, transformation, and automation strategies.
Data Ingestion
The business requirements will determine what sort of processing solution (real-time versus batch) will occur in the pipeline. When we process data in real-time, we are constantly ingesting, transforming, and storing the data as it is generated. In a batch process, the data is moved through a pipeline on a one-time basis, timed schedule, or as it reaches a certain volume threshold.
When the data is ingested, it will be kept in a centralized “Raw Zone” storage. In the raw zone storage, the data is partitioned by source system to maintain basic organization. The data is kept exactly how it appears in its original form. No major data processing techniques or transformations will occur at this stage. By keeping the data in its original form we can migrate the data quickly and ensure it was migrated properly by cross-checking our on-premises systems. In the raw zone data layer, all the data from the source system is stored even if it is not being used further down the pipeline. This keeps the initial ingestion process simpler and allows the pipeline to be expanded easily as business requirements grow, since all the data will be in one place.
We will demonstrate how to ingest data in three different ways. The first method is real-time streaming ingestion from a sample streaming data source, the second is the migration of an on-premise database, and the third is flat file ingestion from a file storage system.
Real-Time Ingestion
For our real-time ingestion, we have a sample script that generates data, and a kinesis producer to write the data to the kinesis data stream. Kinesis Firehose acts as a consumer and takes the data from our data stream and writes it to S3.
- Create a Kinesis Data Stream: When creating a data stream, it is important to specify the capacity. For example, for unpredictable workloads, on demand is suggested. Alternatively, provisioned mode allows you to specify the number of shards allocated that grant certain read and write capacity.
- Write the Kinesis Data Stream Producer: The kinesis producer utilizes AWS SDK to capture data from our streaming data source and write it to our kinesis data stream. In the supplementary files folder, there is a streaming_data.py file. Enter the name of your Kinesis Data Stream created in step 1 to generate and write sample data to the stream.
- Create a CloudWatch Log Group and Log Trail: To enable logging for Firehose, we must specify a CloudWatch log group and log trail.
- Create a Kinesis Firehose Consumer: The Firehose source is configured as the Kinesis Data stream, and the target is configured as the raw zone bucket. It’s important to note that we need to enable dynamic partitioning and specify in the properties to add a delimiter between records. This way when firehose writes to S3, the data will be in a valid JSON format for Glue during processing. When dynamic partitioning is enabled, inline parsing must also be enabled. This is where we specify by which key our data is partitioned. Another specification needed when creating the consumer is to declare which bucket partition the data will be delivered in. For this data stream, the data will be delivered in the “StreamingData” folder of the raw zone bucket. If in the event of an error, the data is sent to a different partition of the raw zone bucket.
Batch Ingestion
The Database Migration Service (DMS) replication instance will connect to the source database through an internet gateway. From there the replication task will perform a full load of our database and place the data in S3.
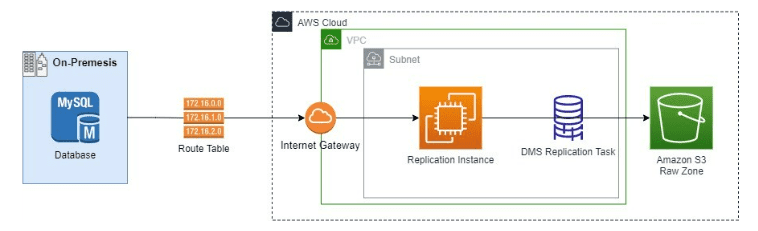
Figure-02
- Store Database Credentials in Secrets Manager: Create a database secret in secrets manager containing the username, password, port, and host of the on-premises database.
- Create a VPC: For the VPC to be used by the AWS Database Migration (DMS) service replication instance, it must have an internet gateway attached and at least two subnets. The route table must send traffic not intended for the VPC to the internet gateway so that we can connect to our database.
- Create a DMS Replication Instance: The DMS replication instance utilizes Ec2 instances. It is important to choose the right type of instance depending on your workload requirements.
- Establish DMS Source Endpoint Connection: The source endpoint connection will be to our MySQL Database. Here the secret created in step one is referenced to get the database credentials for the endpoint connection.
- Create IAM Role for DMS: DMS will need access to our raw zone S3 bucket to write the data from the database.
- Establish DMS Target Endpoint Connection: The target endpoint connection is to the raw zone S3 bucket. Here is where you provide the IAM role created in step 5. In addition, it is important to specify which partition of the S3 bucket the data is going to be delivered in so that it is separated from our other data sources. The endpoint we created will deliver the data to a folder called “BatchData”.
- Create DMS Replication Task: The replication task will use the source and target endpoints created. We can also specify our table mappings for ingestion, this is where we fill out logic to include or exclude certain data. In our mapping we specify to include all tables.
- Run the DMS Replication Task: In the supplementary files folder of the blueprint, there is a file run_dms_task.py. Enter the ARN of the replication task and it will start the task for the one-time batch ingestion.
Flat File Ingestion
Our flat file ingestion will utilize AWS DataSync to move the files to our Raw Zone bucket for consolidation.
- Create IAM Role for DataSync: DataSync will need access to the S3 bucket where the flat files are stored as well as our raw zone bucket.
- Establish DataSync Location for Source Data Store: Using the IAM role created in step 1, we can create a DataSync location for the flat file bucket.
- Establish DataSync Location for Target Data Store: The target data store location will also utilize the same IAM role. Here we also need to specify the S3 partition/folder which the data will be delivered to in the raw zone bucket. In our example, the data will be stored in the “FlatFile” folder.
- Create DataSync Task: Here we specify the flat file bucket as the source location, and the raw zone bucket as the target location. In addition, we can specify that we only want new data to be transferred so that files are not duplicated in our raw zone bucket. In the example, we have the task scheduled to run every 24 hours.
Blueprint
This playbook provides guidance on how to build a data pipeline within AWS including ingestion, transformation, and automation strategies.
Data Transformation
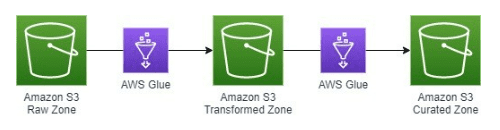
Figure-03
Transformed Zone vs. Curated Zone
Going back to our original problem, we have three data sources that need to be combined. In the transformed layer, our goal is to create a logical schema that combines the three data sources while retaining most of the information from the raw zone layer. The only data that should be excluded from the transformed layer is data that has absolutely no potential for future use (which was determined during the initial analysis). This is because as we extend the pipeline in the future to accommodate for more business use cases, we need to have the data available in the transformed layer. Most of the cleansing transformation logic will happen in the glue job from the raw zone to the transformed zone. Our example transformed layer schema is the following:
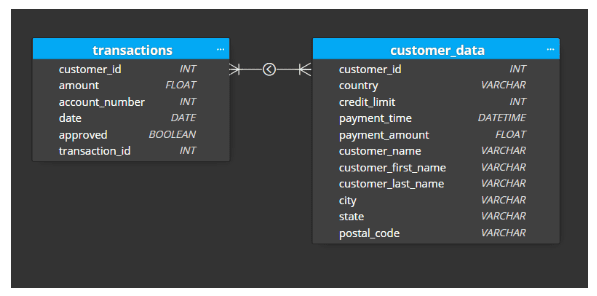
Figure-04
The curated zone is where we create another schema to match specific business requirements. For example, if we have a business unit that needs access to the information in our customer_payments table, but the only payments that are relevant to their country, we would have a customer_data_country table that they can access. If we have another team that needs access to all transaction data, we would have a transaction table. Our curated zone will expand as more and more requirements materialize, and it will be simple to create what is needed since the data is available in the transformed layer. The goal in the curated zone is to further optimize the amount of aggregations our data consumers will need to perform in order to get the information they need. The data is tailored to the consumer which also helps simplify data governance.
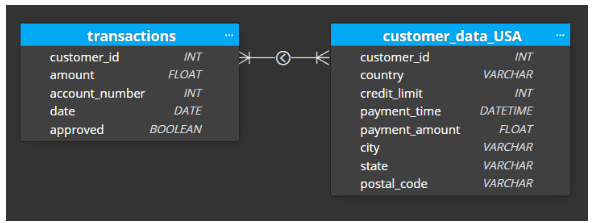
Figure-05
Glue Job Strategies
The transformed layer in the pipeline should follow the structure of the transformed layer schema. It is important to note that moving the data from raw zone to the transformed zone will require multiple glue jobs. A good way to start building the transformation glue jobs is to take it table by table. To create our customer_data table, we need to ingest and combine data from our batch source and streaming source. To organize the data in the transformed S3 bucket, each table from the new schema will have its own partition. So, the data will be moved to the customer_data folder of the transformed S3 Bucket.
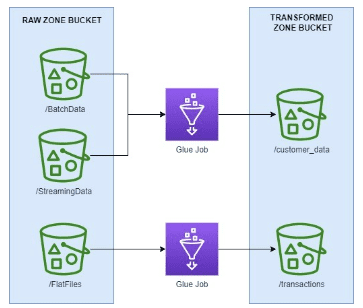
Figure-06
The glue job script will contain logic to join the two sources, perform any other transformations, and map it to the new schema. In the event multiple glue jobs are needed to create a single table, the table folder in the transformed bucket will have a subfolder for each job. That way, the data for the table is consolidated. These glue job strategies also apply for creating glue jobs from the transformed zone to the curated zone.
Whether the glue job is for the raw to transformed layer, or the transformed to curated layer, the process to create the jobs is the following.
- Create IAM Role for Glue: Glue will need access to your raw, transformed, and curated buckets as well as the objects in them.
- Create Partitions in Destination Bucket: Glue will not automatically create a partition in your bucket for each job. If there are many partitions we can utilize the add_s3_partition script to do it faster.
- Create Glue Job: Depending on the volume of your data, glue offers two options for creating ETL scripts: Python ETL or Apache Spark. Apache spark is typically used for larger workloads, while python ETL is used for lighter workloads. With the large amounts of data financial services institutions have, it is more common to utilize spark. The script will specify source location, target location, and any transformation logic.
Glue Jobs Workflow
Our workflow follows the logical order to move the data. The workflow first kicks off the glue jobs needed to get the data from the raw zone to the transformed zone. Once those jobs have been completed, the jobs to move data from the transformed zone to curated zone kick off.
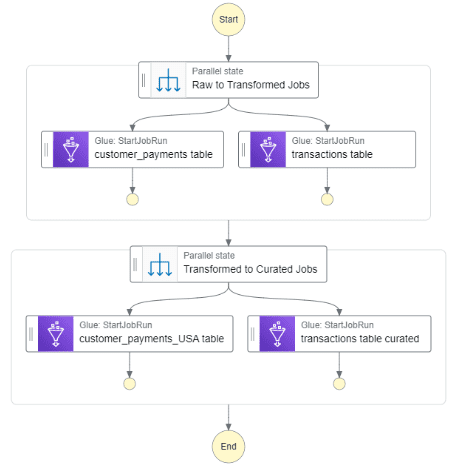
Figure-07
To start the workflow itself, we need to create some sort of trigger. The most common practice is to create a time-based trigger that runs the workflow. For data that is not time-sensitive and for general reporting, it is common to have the workflow run on a daily basis. The process to create the workflow is as follows:
- Create IAM Role for Step Functions: Step functions will need access to our glue jobs and permission to start them.
- Create Step Function State Machine: The step function state machine is where we design the workflow to execute the glue jobs. Here it is important to make sure to specify wait for the raw to transformed jobs to complete before executing the transformed to curated jobs.
- Create IAM Role for Event Bridge: The IAM role for event bridge needs permission to start the step function state machine
- Create EventBridge Rule: In the event bridge rule, we specify that we want our workflow to run on a time based schedule and select our state machine as the target
Blueprint
The Cloud Development Kit (CDK) application that configures all the cloud resources in this project is created from app.py and leverages the data_ingestion and data_transformations classes.
The data_ingestion class is leveraged by the CDK app to create:
- Raw zone S3 bucket
- All resources and permissions needed to ingest data from the streaming source, mysql database, and flat file location
The data_transformation class creates:
- Transformed and curated S3 buckets
- All glue jobs to process the data through the pipeline
- Logical workflow to execute the glue jobs in order
- Trigger to kick off the glue workflow on a schedule
The glue_jobs directory contains:
- Four glue scripts to create our transformed and curated schema
The supplementary_scripts directory contains scripts necessary to:
- Generate sample streaming data and send it to our data stream
- Kick off the DMS task
- Add S3 bucket partitions to match our schema
The workflow_scripts directory contains:
- State machine script that defines the order our glue jobs should be run
The flat_files directory contains:
- The sample flat file used for the ingestion and transformation process
Benefits
- Data from on-premises location is migrated into the cloud reducing operational effort of running on-premises resources
- All data is consolidated and organized in a logical way to minimize the number of data stores that needs to be managed
- Data no longer has to be manually extracted and joined since the transformation logic automatically performs those functions
- Because the transformation logic is automated, users that originally needed access to raw data will no longer have access. This reduces the risk of data theft, leaks, or tampering.
- Data transformation logic is created based on what your business needs – the data is curated for the end-user consumption
- The entire ETL process is automated with a trigger that suits your downstream requirements
End Result
The Data Pipeline Foundations provide guidance on the fundamental components of a data pipeline such as ingestion and data transformations. For data ingestion, we heavily leaned on the concept of data consolidation to structure our ingestion paths. For transforming your data, be sure to utilize our step-by-step approach to optimize architecting your data for end-user consumption. By following the strategies provided, your organization can create a pipeline to meet your data goals.