

A major benefit of cloud computing is the elimination of lifecycle costs for data centers and physical hardware, along with outlays for the redundancy and resiliency of that hardware. AWS takes care of the underlying hardware, its maintenance, and its resiliency. AWS does not, however, guarantee resiliency for your workloads in the cloud. Ensuring the non-functional requirements (NFRs) for an application’s workload are met, such as RTO (recovery time objective, or how long it takes to recover from a failure) and RPO (recovery point objective, or how much data can be lost in a failure), remain the responsibility of the customer. This responsibility for resiliency is outlined in the AWS Shared Responsibility Model
The model leaves all business continuity concerns to the customer, such as the configuration and testing of fault tolerance, backup, and disaster recovery. Recent incidents, such as major outages in US-EAST-1, underscore the necessity of resiliency testing and designing fault-tolerant, scalable workloads. Unfortunately, that incident also showed that many organizations are either not currently performing resiliency testing or are not testing at scale to prevent availability zone or regional disruptions. Data loss and downtime don’t just affect your application workloads – they can also damage customer trust in your brand, and in the financial services industry, bring potential regulatory scrutiny and fines.
Given these consequences, it’s essential that any application provisioned for the cloud be designed with the complexities of distributed computing in mind, then rigorously tested to prove it can meet or exceed NFRs. Resiliency testing is the core tool for demonstrating whether a workload meets or exceeds those NFRs. This foundation provides a strategy and a testing framework for addressing the issues raised by mass outages and proving your workload can meet business needs during and after failures.
Prescriptive Guidance
Resiliency testing can be performed and automated at any stage of a workload’s lifecycle, but we recommend designing your workload from the beginning with resiliency in mind and to design and run automated resiliency testing before entering production, and regularly thereafter to ensure compliance as your workload evolves. Our Resiliency Foundation is built under the assumption that you are designing and deploying your workload alongside and in response to your resiliency testing.
Definitions
- Non-Functional Requirement (NFR) – A requirement that defines how the workload behaves under certain conditions. For comparison, a functional requirement is a technical requirement of the workload, that is, what the workload should do, such as how the workload transforms input data. An NFR would be how the workload scales under load. The VR Resiliency Framework is concerned with NFRs related to business continuity of your workload. The most important NFRs for resiliency and business continuity are Recovery Point Objective and Recovery Time Objective.
- Recovery Point Objective (RPO) – The maximum data loss that can be sustained after a recovery as measured by time, such as five minutes, an hour, or a day of lost data. Lost data can be corrupted, unrecoverable packets, missed transactions, or gaps in critical logs. If a database becomes corrupted and the previous snapshot was thirty minutes ago, and all transactions during the past thirty minutes were not recoverable, the actual recovery point for that database’s workload would be thirty minutes. If your RPO was thirty minutes or greater, the workload would have met resiliency requirements.
- Recovery Time Objective (RTO) – The maximum time it should take to recover from a failure or disruption in your workload. This can also be seen as the maximum downtime your system can sustain due to a failure before the consequences of downtime are intolerable for business operations. A stuck worker node may stop processing data and disrupt an entire workload. The recovery time would be the time between notification of that stuck worker node and resumption of the normal workload, and your workload would meet resiliency requirements if the actual recovery time was under the RTO.
Performance NFRs like Latency and Volume requirements are critical for many customers and often included in Resiliency testing validations. We cover these requirements in more detail in our Performance framework.
Best Practices
Conduct an Architecture Review
Before resiliency testing can begin, stakeholders should work with technical teams on a thorough architecture review. The results of this review will be used to establish NFRs based on expected use and business needs. These NFRs will be used to establish baselines for performance under failure conditions. Additionally, the architecture review should identify potential points of failure that can be tested to prove NFRs can still be met under failure.
Defining NFRs such as RTO and RPO should drive the architectural design of your workload and help you follow resiliency best practices. These NFRs are also critical components of your business requirements, so clearly stating them will ensure your design can meet or exceed business needs. Here are some questions you can ask to assist your review process:
- Customer expectations/SLAs – What is the maximum time your workload can be inoperable for within a certain period before breaching contracted agreements with your external and internal customers? What is the maximum data loss that can be sustained before those same agreements are breached?
- Workload scalability – What is the maximum traffic the workload is expected to receive, and how and in what direction should the infrastructure scale to meet your customer needs?
- Attack surface – Business disrupting security events and attacks are increasingly common. Should your failure testing include attacks that can prevent business operations, such as a DDOS?
- Disaster recovery – How resilient to large-scale failure does your workload need to be to meet requirements? Is a multi-region deployment necessary to ensure global business continuity?
- Trade-offs and costs – Resiliency requirements add cost and complexity to workload and infrastructure. Are your desired NFRs in line with your schedule and budget?
Robust architectural diagrams of your workload should be developed during this step to assist you in identifying every potential point of failure or disruption.
Additionally, there are AWS Services and tools that can assist your teams in discovering points of failure, attack surfaces, or gaps in redundancy. The AWS Resiliency Hub can assist in developing resiliency requirements and testing. The AWS Well-Architected Tool can be applied to workloads to analyze how they conform to well-architected practices, while AWS Trusted Advisor provides alerting on configurations within your account that could lead to a quota limit, security, or scaling issues. AWS also offers the Resilient Architecture Readiness Assessment(RA2) to review the resilience of a cloud workload.
Create Resiliency Test Cases
After performing an architecture review, you should have clear requirements your workload needs to meet and a thorough understanding of potential points of failure within your infrastructure and application. Using this data, you can write test cases to test your workload. These test cases should be targeted, granular, and scale to reach the maximum predicted traffic and infrastructure for your workload.
Use the answers from your questions in the previous step to identify input/output chokepoints, points of failure, and other potential weaknesses within your workload. Design tests around this information. Referencing the architecture diagram that you created during the initial architecture review will help narrow test cases to specific services. Essentially, every time data moves from one service to another, there should be a test case for every potential failure that can occur in either service. Certain services can have multiple failures to test, such as EC2, which has many potential areas for failure including high CPU usage, memory usage, or DNS resolution failure. Each of these failures should be separate test cases.
Non-functional components of your workload should also be tested. For example, you should test what happens when your monitoring or logging system is disrupted or fails . Even though they are not functional parts of your workload, these auxiliary systems provide critical business needs. Ideally, any failure introduced by your testing should generate alerts that are sent to the appropriate teams, and any metrics relevant to the failure should continue to be gathered during the event along with meaningful errors within your logging system.
Test Flow
A well-designed resiliency test has similar steps regardless of the framework that executes it. Every test should clearly identify what it is testing in the title, e.g. “Kubernetes ETL Worker Node Inbound/Outbound Network Connectivity” if you are testing a node in a Kubernetes cluster that is doing ETL work within your application. The test steps should be clearly described and should include
- Identification of the service to test and how many instances (e.g. are you performing a test on one, or many EC2 instances)
- Load generation to begin the workload, how much load the test should introduce, and for how long the full test should run
- The failure to be introduced, how it should be introduced, and for how long the failure condition should last (e.g. root volume exhaustion on an EC2 node, using dd to fill the volume, and continuing this failure for three minutes)
- Validation of the system’s response to failure by measuring data loss or downtime, along with validating appropriate monitoring and alerting is triggered by the failure.
Vertical Relevance has a library of tests that can be quickly leveraged by your company and made to fit any workload.
Write and Automate Resiliency Test Actions and Probes
Your team should have prepared many test cases in the previous step to run against your workload. While the tests are being prepared, actions can be developed that will initiate the desired failure states required in the test, along with probes that can query application state to understand and verify the health or failure of the workload.
To embrace an automation-forward approach to resilience testing, both the target infrastructure and resilience test actions and probes should be defined as code. Defining the test infrastructure and actions/probes in code allows for the test deployment and execution to be automated, saving significant time and allowing for quick iteration of your tests as your workload changes.
Automation of your resiliency tests and defining them in code should include every step of the test including
- Deploying the infrastructure to be tested (if necessary)
- Generating the load on the application
- Injecting the failure using actions
- Using probes to validate the infrastructure and application response
- Generating reports from the failure; including verifying RTO, RPO, and other NFRs and that appropriate alerts and logs are generated
- Automatically passing or failing the test based on probe responses
- Spinning down the infrastructure
Manual resiliency testing can be done if results are needed before automation is in place, but Vertical Relevance recommends an automation-first approach to resiliency testing.
Execute Tests and Remediation
Resiliency tests should be executed when your workload and infrastructure are mature enough to handle your expected load, but before production deployment so high-severity issues uncovered in testing can be remediated accordingly. After analyzing the test results and comparing them against your NFRs, you should use these meaningful findings to make strong and precise recommendations for improvement.
Resiliency tests should be executed when your workload and infrastructure are mature enough to handle your expected load, but before production deployment so high-severity issues uncovered in testing can be remediated accordingly. After analyzing the test results and comparing them against your NFRs, you should use these meaningful findings to make strong and precise recommendations for improvement.
For example, if your workload does not perform to expected NFRs for data loss (i.e. RPO) under a given failure scenario, the application team can implement a solution addressing the issue, and the resiliency test could be repeated to prove the solution is a good fix. Robust automation of tests and testing infrastructure greatly aids rapid and repeated test execution, leading to a more agile development cycle.
Resiliency Automation Framework
Resiliency testing is an evolving practice, and there’s a growing abundance of tools and platforms to assist in writing resiliency tests, some of which may call themselves fault-injection or chaos engineering tools, such as AWS Fault Injection Simulator and Gremlin. For this solution, we will be using Chaos Toolkit to define our resiliency experiments. The Chaos Toolkit experiment specification allows us to define actions in Python that can be chained together and applied to a workload to generate load, inject failures, validate results, and create reports. Vertical Relevance has a library of actions and probes, along with an automated build and execution process that can be used to perform any test written using the Chaos Toolkit specification, including numerous tests already prepared.
Components
Our framework consists of the following services:
- Infrastructure as Code – As an automation-forward practice, we use CodePipeline, and CodeBuild to create and tear down the testing infrastructure, all defined in CDK
- AWS CodePipeline – Controls the flow of builds for the Resiliency Python code package and the Resiliency Lambda
- AWS CodeBuild – Builds the Resiliency Code Package and Lambda within CodePipeline
- AWS CodeArtifact – Stores the Resiliency Code Package in a repository for use with pip when building the Lambda
- AWS Lambda – Runs the Resiliency Experiments against the workload infrastructure
- AWS SSM – Some the failures must be initiated on a specific instance, such as high CPU or blocking access to a database, so SSM Documents are used to perform these on a shell
- AWS S3 – Stores the experiment files and post-experiment reports detailing the effect the failure had on the infrastructure
- Chaos Toolkit – The open source experiment framework and tool that runs our resiliency experiments
- Experiments – These are YAML files as defined in the Chaos Toolkit specification. The extensible experiment framework of Chaos Toolkit allows for robust, targeted functional testing of a failure state. These files are stored in an S3 bucket
- Actions and probes – These are functions defined in Python. Actions initiate failure states, and probes validate health and the response of the workload to failure. We package these in a library, a subset of which is included in the blueprint below. There are also actions to generate load on you application, gather metrics, and generate reports for later analysis so you can automate test execution and validation. New functions can be added as test cases call for them
- Author – The member of the team that writes the Python actions and probes, as well as the YAML experiment files for resiliency testing
- Operator – The member of the team that runs the tests and potentially analyzes and synthesizes the results of multiple tests to gauge the workload’s resiliency against the requirements. Can be the same person as the author, of course
How it works
The Vertical Relevance Resiliency Automation Framework helps your team jump into resiliency testing at any point in your development lifecycle. Though Vertical Relevance has a deep library of tests and code already written, a sample of which is provided in the blueprint, the Resiliency Automation Framework can be extended to test all possible workloads in AWS.
Like any resiliency testing development process, using our framework begins with an architecture review and definition of requirements, followed by the creation of the test cases that fit the architecture and requirement. When necessary, test cases for the workload will be written to augment existing tests in the library so that the workload is fully vetted. These earlier steps in the process follow the best practices for architecture review and test case creation defined earlier in this playbook. Our testing framework provides tools and processes for the later steps of test action creation, automation, and execution. Let’s go into more detail on these steps and how they accelerate the resiliency testing process.
The diagram below shows the basic workflow for our framework.
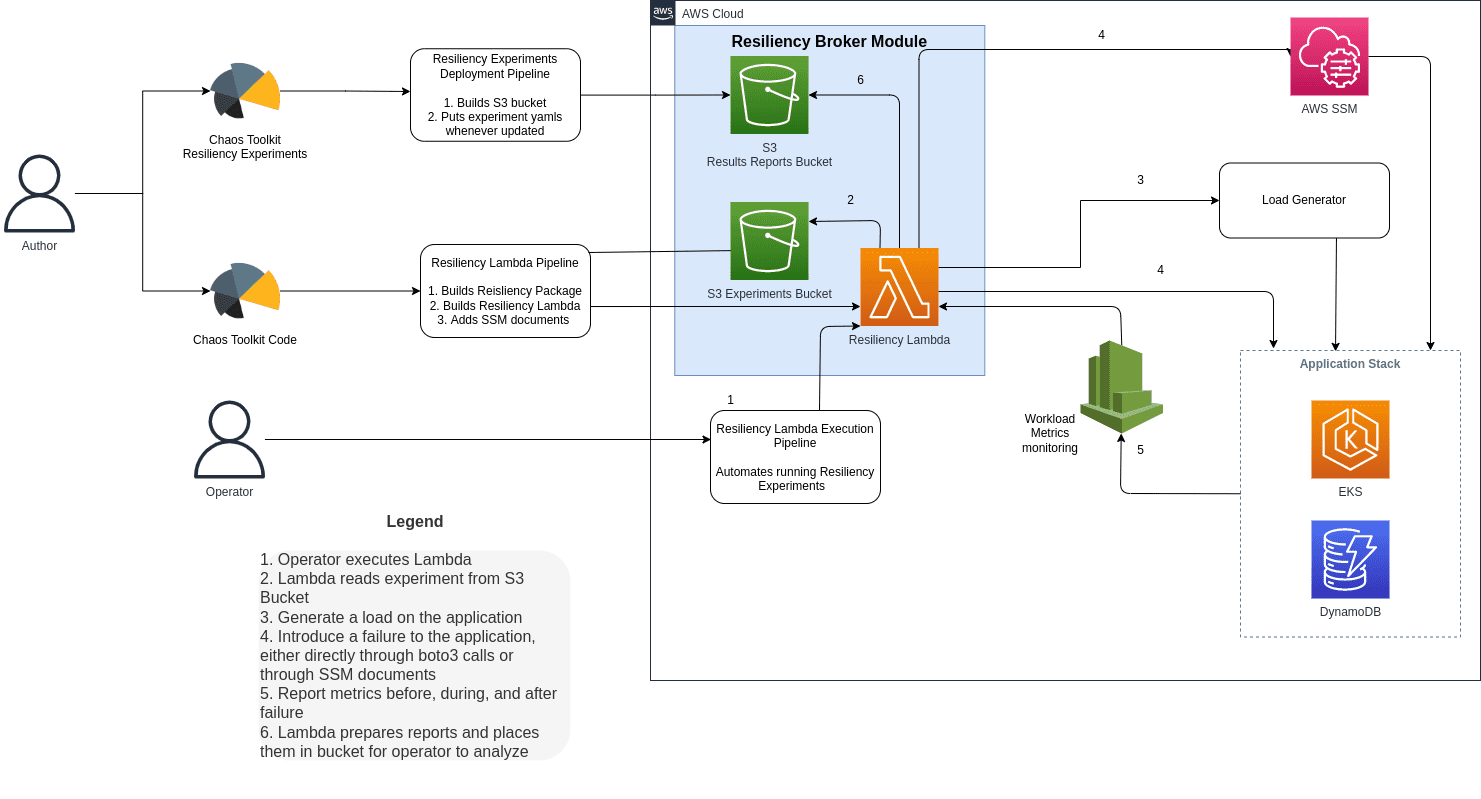
The process begins with the author(or authors) creating experiment files for each test case . These experiment files will use probes that check the health of the workload to ensure it is running normally. Establishing the baseline health of the system in this way is called the steady-state hypothesis in the Chaos Toolkit framework. Once workload health is verified, the experiment will generate a known amount of traffic so the effects of the failure can be measured. This load could be ten thousand transactions on a database, for example. Since the quantity of the traffic is known, the loss incurred by the failure can be measured. The experiment will then initiate the failure state as defined for the test, such as terminating a worker node. The experiment file will also query any alerting system to ensure appropriate alerts were triggered. Probes can query the application and pull metrics to automate reporting on and validation of required NFRs such as data loss(RPO), downtime(RTO), latency, and volume issues the failure brought about.
Our blueprint for the Resiliency Automation Framework includes two example experiments that follow the Chaos Toolkit experiment format: one that stresses EC2 instances with high RAM usage, while the other will terminate EC2 instances that are part of a workload. Both of these experiments use actions that are defined in Python code, relying on the Boto3 library to perform the failure injection. The experiment that stresses memory usage relies on an SSM document, which is also included in the blueprint. Both experiments only include the action, and not any steady-state hypothesis, load generation, or reporting, as those are application-specific, however, the actions included are representative of the experiments within our library. For a fuller discussion of the experiments and associated code, please see our blueprint README.
Once the experiments and test actions are written, the operator can execute the experiments. Tests can be run as soon as an experiment and corresponding code are written; you don’t have to wait to get all your tests and actions written to begin testing. In the Vertical Relevance Resiliency Framework, we use an AWS Lambda to run experiments serverlessly. Using Lambda allows multiple operators to run tests with minimal intervention and simplifies testing permissions and infrastructure. We include a lightweight Boto3 script in our blueprint as an example of how to invoke the Lambda programmatically, and we recommend this script be incorporated into an existing CI/CD pipeline or other automation system so tests can be run rapidly and successively.
Testing at scale can be time-consuming, even when using a framework to ease the process. Vertical Relevance has an automation-first approach in all of our work, and our Resiliency Framework is designed to be automated as well. Packaging and deploying the resiliency code and infrastructure should be done within a CI/CD pipeline. Our blueprint uses CodePipeline and CodeBuild defined in CDK to automate the deployment process, but any CI/CD system and IaC framework could be used.
Blueprint
The Resiliency Blueprint repository contains sample actions and experiments from our Resiliency Automation Framework, and an AWS Lambda handler to run the experiment. It also contains AWS Cloud Development Kit (CDK) code to deploy everything necessary to run the sample experiments.
The cdk_pipelines directory contains CDK code for creating two CodePipelines: a pipeline for building and uploading the resiliencyvr python package that contain the Chaos Toolkit Actions and Probes, and a CodePipeline for creating the lambda that will incorporate the resiliencyvr package and run the experiments.
Benefits
- Resiliency testing provides confidence to your customers in your workload’s ability to weather minor and major disruptions without impact on business operations, even up to a regional failure
- Thorough testing helps you discover your unknowns by rooting out edge cases, hard to find bugs, and gaps in your workload infrastructure so you can fix them before they affect your workload in production
- Full functional testing of your environment demonstrates the ability of your workload to scale as necessary
- Resiliency Tests also exercise your metric and alerting infrastructure, giving your SRE and DevOps teams confidence in their observability and introspection stacks, which leads to fewer bad surprises when an event occurs
- Outages and data loss damages customers’ confidence in your product and harms your brand. Resiliency testing guards against this damage by ensuring your workload does not fail unexpectedly
- In financial services, data loss or outages can also bring regulatory scrutiny, injunctions, and fees or fines. Resiliency testing must be a part of any financial service solution in the cloud to prevent failures that could lead to regulatory outcomes.
End Result
Building your workload in the cloud can simplify hardware procurement and maintenance, but it doesn’t mean you’re safe from failures in your application and infrastructure. Regular and robust resiliency testing provides assurances your cloud application can weather whatever outages may occur. The Vertical Relevance Resiliency Automation Framework can help guarantee your workload can prevail through disruptions and failures and prevent the damaging consequences of an outage. Reach out to us to learn more about how we can help you meet your resiliency requirements.