

Rapidly deploy and execute experiment tests in your AWS environment
Overview
Data loss and downtime are significant risks for organizations in the financial services industry. Any lost data or application downtime can impact customer satisfaction, damage an organization’s brand, and potentially bring costly regulatory scrutiny or fines. Thorough experiment testing helps you discover unknowns in your infrastructure and application, limiting potential downtime and data loss by learning how your system can fail and how to build in tolerances for that failure. The Vertical Relevance Experiment Module provides a quick path to setting up resiliency testing infrastructure in any AWS environment, so you can begin testing your application.
Problem Statement
The AWS Shared Responsibility model provides assurances for the reliability of the underlying hardware your AWS applications run on, but not for your application. Have you produced requirements for uptime and data integrity (also known as non-functional requirements, or NFRs) for your application? Have you tested your application under failure conditions to ensure those NFRs are met even when part of your application fails?
Applications fail, whether on-premises or in the cloud. Failures negatively affect outcomes for uptime and data integrity. Testing resilient and fault-tolerant infrastructure is a critical step in designing any cloud application, ensuring that your application can withstand failures and still deliver.
The Vertical Relevance Experiment Module provides a quick start to testing application failures to discover how they affect your business deliverables.
Below is a matrix that outlines two primary problems that are addressed by the Experiment Broker.
| Problem | Details |
| Points of failure affect NFRs in unknown ways | Without a thorough review, points of failure, including single points of failure, can go unnoticed. This often leads to downtime and loss of data in unexpected events. For many financial services organizations, downtime and data loss are unacceptable, and either could lead to negative business outcomes, or unwanted regulatory scrutiny. Even when potential points of failure are identified, their effect on the application is unknown until tested. Certain failure types may be acceptable, or the costs associated with remediation may be untenable. |
| Discovering and remediating failures is time consuming and costly | Every application is at risk of failure. Unfortunately, subpar resiliency testing approaches within lower environments and slow response plans in production often lead to negative impact on end user experience. Specifically, when these failures make their way into production environments, every second matters and it is critical to remediate the root cause and re-establish a positive end user experience as quickly as possible. |
Experiment testing is still a relatively new field, and comprehensive tools are still being developed. The Vertical Relevance Experiment module leverages portable code and an extensible framework to quickly design, write, and execute resiliency tests across a variety of environments.
Solution
Vertical Relevance’s Resiliency Foundation provides an automation-first framework for designing, writing, and executing experiment tests across any AWS environment. The Resiliency Foundation addresses the above challenges by giving Financial Services organizations an extendable framework and examples to build a robust resiliency testing strategy.
It’s important to note that test creation and execution should only happen after careful evaluation of your application’s non-functional requirements, including your Recovery Point Objective (RPO) and Recovery Time Objective (RTO). These requirements provide baseline behavior for your application and determine the resiliency goals your application needs to meet. These requirements should be identified while designing your application so you can develop it with resiliency in mind.
This blog post will explain the technical details of the framework, which we call the Vertical Relevance Experiment Module, including the automation leveraged to deploy the framework, structure tests, and execute experiments. This solution does not cover the preliminary steps of architecture review and composition of experiment tests – for more information on these topics, refer to our Resiliency Foundation Solution Spotlight.
Components
The Vertical Relevance Experiment Module provides a baseline
- Infrastructure as Code – As an automation-forward practice, we use CodePipeline, and CodeBuild to create and tear down the testing infrastructure, all defined in CDK
- AWS CodePipeline – Controls the flow of builds for the Resiliency Python code package and the Resiliency Lambda
- AWS CodeBuild – Builds the Resiliency Code Package and Lambda within CodePipeline
- AWS CodeArtifact – Stores the Resiliency Code Package in a repository for use with pip when building the Lambda
- AWS Lambda – Two lambdas are used here: one to convert plain text to the JSON format needed by the second lambda, which itself executes Resiliency Experiments against the workload infrastructure
- AWS Step Function – Coordinates execution-related lambdas, primarily looping the execution lambda through a list of experiments to run
- AWS SSM – Some failures must be initiated on a specific instance, such as high CPU or blocking access to a database, so SSM Documents are used to perform these via shell
- AWS S3 – Stores the experiment files and post-experiment reports detailing the effect the failure had on the infrastructure
- Chaos Toolkit – The open-source experiment framework and tool that runs our experiments
- Experiments – These are YAML files as defined in the Chaos Toolkit specification. The extensible experiment framework of Chaos Toolkit allows for robust, targeted functional testing of a failure state. These files are stored in an S3 bucket
- Actions and probes – These are functions defined in Python. Actions initiate failure states, and probes validate health and the response of the workload to failure. We package these in a library, a subset of which is included in the blueprint below. There are also actions to generate load on you application, gather metrics, and generate reports for later analysis so you can automate test execution and validation. New functions can be added based on the requirements of new test cases
- Author – The member of the team that writes the Python actions and probes, as well as the YAML experiment files for resiliency testing
- Operator – The member of the team that runs the tests and potentially analyzes and synthesizes the results of multiple tests to gauge the workload’s resiliency against the requirements. Can be the same person as the author, of course
Implementation Details
Overview of Experiment Module Code
The Vertical Relevance Experiment Module is comprised of two distinct repositories to allow for maximum deployment flexibility and to demonstrate deployment examples. The core Experiment Broker repository houses the Python library of actions and probes used by the experiments, as well as the execution lambda that incorporates that library. The second repository contains the AWS CDK for the Experiment Pipeline, which deploys the pipeline which the necessary infrastructure for running resiliency experiments within an AWS environment. Another functionality of the pipeline is to retrieves a file from s3 contains a Json format of experiment and the location in s3, then executes the state machine which orchestrates the execution of experiments.
Separating the repositories allows for flexibility in deployments. Although we use CDK with CodePipeline to deploy in our example, the core Experiment Broker code can be adapted to any CI/CD pipeline for deployment. We’ll go into each repository in more detail in this blog, beginning with the core Resiliency Broker code.
Below is a high-level overview of the architecture of the solution.
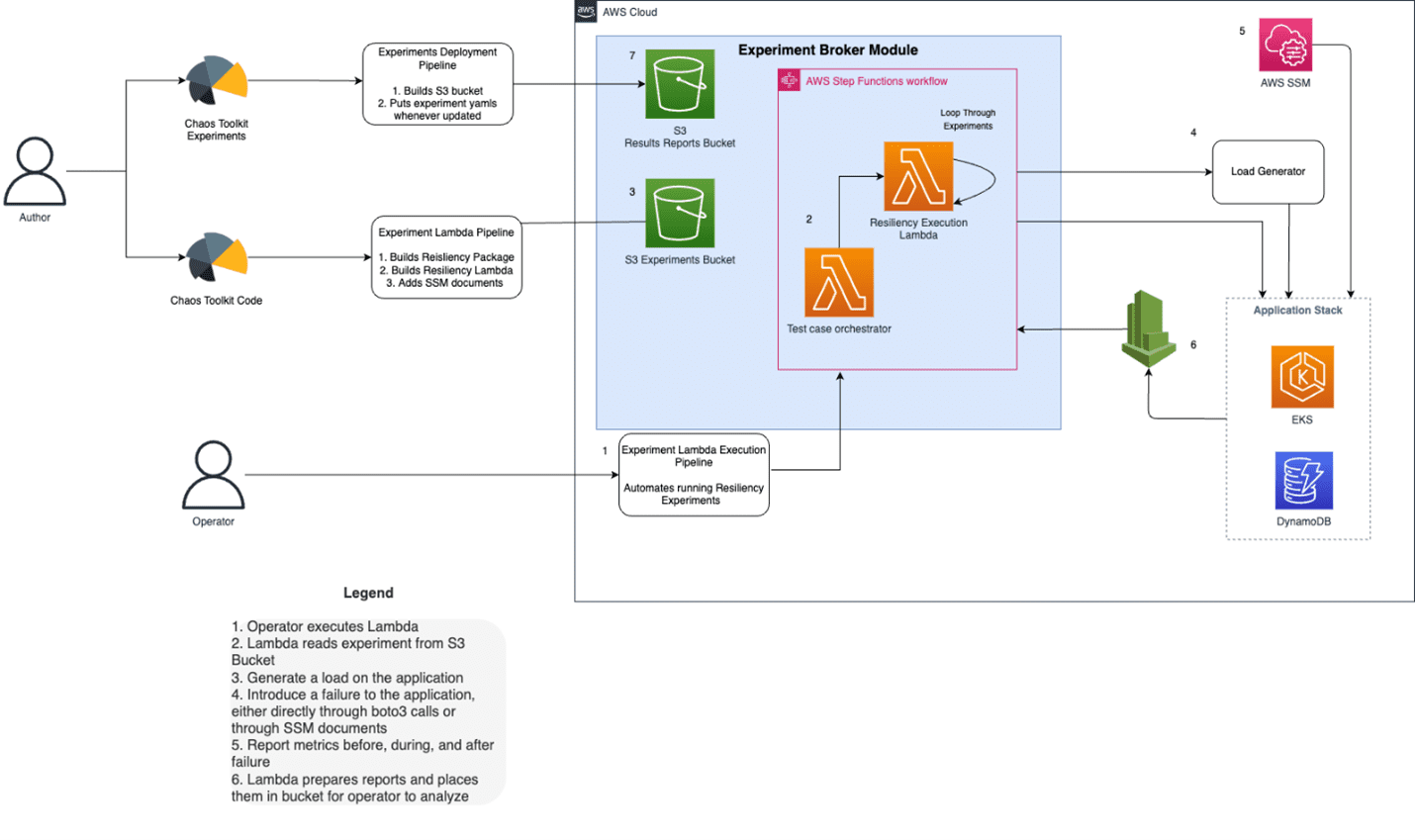
Figure-01
Anatomy of a Resiliency Experiment
An understanding of the Vertical Relevance Experiment Broker code requires an understanding of some foundational concepts that are part of the Chaos Toolkit open source framework, which our code leverages to ensure a standard and extensible API for resiliency actions and probes and a declarative, human-readable format for resiliency experiments. A good way to understand these concepts is through an example test. We include two very basic tests in our Experiment Pipeline repository. Below is one of them, a test that will terminate a random EC2 instance matching certain tag values within an account.
version: 1.0.0
title: EC2 High Memory Utilization
description: This Experiment will stress an EC2 instance by overutilizing its memory
tags:
- stress-memory
configuration:
aws_region: 'us-east-1'
test_instance_tag_key: 'tag:Name'
test_instance_tag_value: '*.resiliency.local'
method:
- type: action
name: stress-instance-memory
provider:
type: python
module: experimentvr.ec2.actions
func: stress_memory
arguments:
targets:
test_target_type: 'RANDOM'
tag_key: ${test_instance_tag_key}
tag_value: ${test_instance_tag_value}
region: ${aws_region}
duration: '300'
number_of_workers: '1'
memory_percentage_per_worker: '99'Let’s look at this in-depth, line-by-line from the top. The first thing you will notice is that it is a YAML format, but it is worth noting we can also use JSON as well. The first four keys are metadata for the experiment, including a version you can increment as you change the experiment, and tags for grouping experiments together. The sixth line introduces the configuration block, which can have nested keys that act as variables within the experiment.
The method block is the core logic of this experiment. It introduces actions and probes that are part of the failure scenario. For the sake of simplicity, only one action is taken, stress-instance-memory, in this experiment, but multiple actions or probes could be defined. Actions act on your system in some way, such as generating load or introducing a failure, while probes query the system to report information on its state. In a typical experiment, multiple actions and probes would be chained together to perform actions, then report back on the state.
There are two other types of blocks an experiment can have: the steady-state-hypothesis and rollback blocks. The steady-state-hypothesis block runs before the method block and consists of probes to ensure your system is operating normally before you introduce the failure. The rollback block contains actions to return the state to nominal operating condition after the failure. Both blocks are unique to the application you are running, so we do not include them in this generic example.
The provider block is nested within the action block and declares how the action is to be executed. In this case, it’s calling a Python function. Every probe or method must resolve to a function available to the executing system — in this example, we use an AWS Lambda function. The lambda executing this experiment must be built with the code to run the stress-instance-memory function in the resiliencyvr.ec2.actions Python namespace. That code is included in the Resiliency Broker module. Let’s look at this action in more detail to understand how experiment actions work, and how your experiments can be extended using custom actions and probes.
import logging
from typing import List
import boto3
from botocore.exceptions import ClientError
from experimentvr.ec2.shared import get_test_instance_ids
def stress_memory(targets: List[str] = None,
test_target_type: str = None,
tag_key: str = None,
tag_value: str = None,
region: str = None,
duration: str = None,
memory_percentage_per_worker: str = None,
number_of_workers: str = None
):
test_instance_ids = get_test_instance_ids(test_target_type = test_target_type,
tag_key = tag_key,
tag_value = tag_value,
instance_ids = targets)
parameters = {
'duration': [
duration,
],
'workers': [
number_of_workers,
],
'percent': [
memory_percentage_per_worker,
]
}
session = boto3.Session()
ssm = session.client('ssm', region)
try:
ssm.send_command(DocumentName = "StressMemory",
InstanceIds = test_instance_ids,
CloudWatchOutputConfig = {
'CloudWatchOutputEnabled': True},
Parameters = parameters)
except ClientError as e:
logging.error(e)
raise
return(True)
The first thing to note is the mapping between the experiment and the function, namely, the func value and argument keys in the experiment map to the name of the function and its arguments in the code. During the execution of the experiment, the execution runtime calls our Python function directly and must pass in values for each argument or accept defaults as declared in the code. The rest of the code gets one or more target EC2 instance ids to effect the failure on using another custom function defined in our Resiliency Broker code, then runs an SSM document called StressMemory on the target instance(s). The SSM document (which is included as part of the Resiliency Pipeline deployment) does the work of hogging memory by running stress-ng on our target instance(s) but from the perspective of the experiment that indirection is immaterial. The action just needs to do something, then subsequent actions or probes can be run to perform further failures, or report on the state of the system.
Though this is a simple example, it provides a glimpse into the extensibility of the Resiliency Framework. It’s important to note that certain actions are built into the Chaos Toolkit Library and can be used immediately. These actions include common AWS failures and failures for other platform and applications.
Experiment Module Step Function
The module includes deployment code for an AWS Step Function that the execution Lambda will run within. The workflow for the Step Function is shown in the architecture diagram above, but we’ll detail its purpose in this section. The Purpose of the step function is to Coordinate execution-related lambdas, primarily looping the execution lambda through a list of experiments to run. The Step function invokes a lambda in which returns a list of experiments in Json, an example of this payload looks like this:
{ “state”: “in-progress”, “list” : [{“experiment_source”: “path”, “bucket_name”: “bucket”, “state”: “pending”}]}
The state machine receives this payload and loops through list of experiment, processes based on the experiment state and only proceeds to break loop when state is completed.
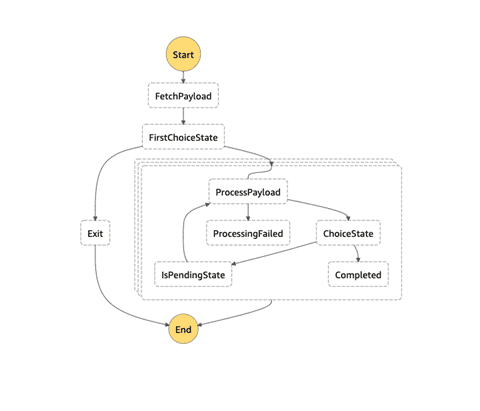
Figure-02
Solution Mapping
The Experiment Module gives SRE and DevOps teams baseline tools for running a variety of resiliency experiments across any AWS environment and on any application in the cloud. The SRE and DevOps teams can provide feedback to Application teams based on reporting from the experiment tests. Using the automation inherent in the Resiliency Module to quickly deploy testing infrastructure using a CI/CD system like CodePipeline, and rapidly run multiple tests using AWS Step Functions, teams can identify and remediate potential failures early and often to improve the resiliency of the application. That way, your teams don’t have to wait until a costly failure to fix issues and can spend more time improving the application.
| Problem | Solution | AWS Services |
| Points of failure affect NFRs in unknown ways | Running resiliency tests that target potential points of failure with you application provides your organization and your customers with assurance that your application can withstand interruptions of service and other incidents. Your teams will have fewer incidents draining their attention, and they’ll be able to deliver new features that improve on the application instead of putting out fires. | – Resiliency experiments executed by AWS Lambda report on points of failure and their effects |
| Discovering and remediating failures is time consuming and costly | Putting effort up front to discover issues will save costly effort in the future. If that’s not an option since your application is already live, automated and easily deployed testing infrastructure and rapid testing gives your teams quick turn around on finding, reporting, and fixing problems before they cause problems for you and your customers | – AWS CodePipeline can be used to quickly deploy the resiliency testing infrastructure – AWS Step Functions can be used to run tests rapidly in succession |
Summary
At its core, a self-contained Experiment Broker provides the Infrastructure to implement automated resiliency experiments via code to achieve standardized resiliency testing at scale across your whole organization. Vertical Relevance’s Experiment Broker is a resilience module that orchestrates experiments with the use of state machines. The input is driven by a CodePipeline that kicks off the state machine but also can be executed manually. Coupled with a deep review and design of targeted resiliency tests, Experiment Broker can help ensure your AWS cloud application will meet business requirements in all circumstances.
Related Solutions
The Resiliency Module streamlines the resiliency testing infrastructure that the Resiliency Foundation introduced. The Resiliency Foundation provided a comprehensive overview of application resiliency evaluation and testing. From architecture review, to experiment design, and through test execution. This Resiliency Module built on these concepts to provide a deep dive into the tools and code.