

Overview
A Data Mesh is an emerging technology and practice used to manage large amounts of data distributed across multiple accounts and platforms. It is a decentralized approach to data management, in which data remains within the business domain (producers), while also making data available to qualified users in different locations (consumers), without moving data from producer accounts. It is a step forward in the adoption of modern data architecture and aims to improve business outcomes. A Data Mesh is a modern architecture made to ingest, transform, access, and manage analytical data at scale.
Most organizations face the challenge of having a “frozen lake” which means business users are unable to access the data they need from their data lake. A data lake is an enterprise-wide centralized data repository and is managed by technical teams who have technical expertise, but little insight into the business context of their data. Since business users are not managing the pipeline or processed data, cross domain usage of their data is a big challenge.
In the current state of data lake or lake house architectures, data meshes are not leveraged which leads to lengthy data delivery times for consumers. In some scenarios, data is even moved to different accounts to provide access – this creates significant risk and maintainability issues. In addition, data explosions (rapid exponential increase in data) can overwhelm the Central Data Repository team’s task to provision accurate, consistent data within SLAs when data meshes are absent from the architecture.
Instead of consuming, processing, and provisioning data from a centralized place, a data mesh treats each domain of an organization as a unique producer of the data they own and consumer of the data they need. Each domain controls the ingestion, cleansing, transformation, and integration of their own data. All domains manage and control their own data and the domains are connected through a central catalog to ensure cross-domain data access, data governance, and data standardization. In this approach, each domain has the power to own and manage their data without the risk of a security breach, using inconsistent technology, or generating data quality issues.
Prescriptive Guidance
Before diving into the Data Mesh solution, it is important to acknowledge that it is a paradigm shift in the way data platforms are architected and managed. Depending on the use cases, the complexity of the solution will vary. There are also many conceptual considerations to think about before creating a data mesh solution including, but not limited to, designing a Lake House architecture first – please see our Lake House Foundations solution for prescriptive guidance on the topic.
This solution will provide a blueprint for a data mesh for an enterprise with multiple producer and consumer accounts, all while keeping automation, scalability, and security in mind.
Definitions
- Producer Accounts – Producer accounts are the data sources in the data mesh. They are where the data resides within the data mesh. The data within the producer accounts is indexed by the central catalog and linked to the consumers.
- Consumer Accounts – Consumer accounts are the end customers of the data mesh. They access the central catalog, to create data links that refer to the producer accounts. Consumer accounts read from the producers without redundantly storing any of the data from the producers.
- Central Catalog Account – The central catalog stores the index of the producers that are registered within the data mesh. It is comprised of AWS Lake Formation (LF) permissions and an AWS Glue Catalog. Producers and consumers both interact with the central account instead of interacting with each other directly.
- Source Systems – Upstream from the producer accounts, source systems can be applications, on-premises databases, APIs, or data streams that feed the producer accounts with data.
- Target Systems – In any ETL job, the target system is where the data ends up being moved to. In some cases, the producer accounts may be target systems for on-premises data sources. In other cases, there may be on-premises systems or applications that need to receive data downstream of the data mesh that could be defined as target systems.
- Data Steward – An administrator responsible for maintaining the LakeFormation tag-based access controls (TBAC) for the data and granting access to users.
Best Practices
Decentralized Data Architecture
As companies mature in their AWS adoption, they tend towards decentralizing their data infrastructure. Decentralized data infrastructure models the way businesses actually produce and consume data by allowing individual sectors of the business to control the data that they produce, while centralizing and standardizing data interfaces and governance. Decentralized data infrastructure also benefits consumers by allowing different business units to integrate data with the software that they use in a way that works for them. Data mesh helps organizations accomplish these objectives by providing a decentralized data architecture solution that meets enterprise needs for governance and standardization.
Centralized Data Catalog Account
The Centralized Data Catalog account houses the data catalog from all the accounts of the enterprise. Producer accounts should be able to register and create a catalog entry into central catalog account and we recommend developing an interface to register a data entity within the central catalog’s system in more mature implementations. A glue crawler can be used from the central catalog account to scan a producer account data entity register the data to the central catalog account. It is imperative that the central account only hold the catalog information and that no other data is stored in the central account.
Lake Formation Tag-Based Access
Vertical Relevance recommends controlling access to LF data resources based on tags. A data steward creates LF tags and assigns tags to resources. Policies are created on a smaller number of logical tags instead of named resource policies. LF tags enable categorization and exploration of data based on taxonomy which reduces policy complexity and permissions management. It is easier to create and manage LF tags than thousands of resource based access policies. It is most efficient to create LF tags based on business domains, data classification categories, departments, and subject areas.
Multi-Level Tagging Strategy
To achieve fine-grained access control, LF tags should be attached at each level of data objects. While different use cases require tags to be attached at different levels (database, table, or column), we recommend that you include tags at each level to allow flexibility in fine-grained access control. It is important to note that if LF tags are not assigned, the object inherits the LF tag from its higher-level object (i.e. if a column does not have a tag it will inherit the tag from its table)
Automated Producer and Consumer Account Setup
Since data mesh solutions require the implementation and ongoing maintenance of many components, automating the following processes is critical.
- Producer account setup
- Adding new data source in producer account
- Consumer account setup
- Adding tag-based access permissions for consumer account
- Adding low-level grants for individual users
Automating these processes allows the administrative work for the system to be integrated with enterprise grade IT, Security, Data Governance, and Access Management systems. Some of this automation is not included in the blueprint but should be part of a mature enterprise-grade data mesh implementation.
Ongoing Access Management
As your data mesh solution matures, you should adhere to the following security and access management rules.
- Provide LF tag-based access to consumer account
- Grant only required permissions to consumer account
- Let consumer account admin manage their internal user access
- Share the LF tags with the consumer account. It can be re-used by the consumer account
- Avoid granting database permissions to the consumer account
Overall Architecture
The data mesh architecture leverages a collection of AWS data management tools to support a specialized, enterprise-grade data lake. The key differences between a data mesh and a traditional data lake center are the ways that data is stored. In the data mesh, data is stored in a decentralized manner and the accounts that produce the data can be easily onboarded into the data mesh without having to perform ETL. This simplifies the data onboarding process, helps prevent data loss or “telephone effect” when data is transferred to different schemas and formats, and reduces redundant data storage. Any data store that is compatible with AWS glue can be leveraged by the data mesh – this includes S3, Redshift, Aurora, RDS, DynamoDB, and more.
For this demonstration, we will focus on S3 as a data storage mechanism since it is one of the most common use cases.
Components
- AWS Lake Formation – Service that provides a way to set up a centralized, curated, and secure Lake house. We leverage Lake Formation to manage access to cross-account data
- AWS Glue – Service that provides extraction, transformation, and loading (ETL) capabilities. We use Glue to applu transformation logic to our data including join operations, filters, and schema mapping, and delivery to the specified destination
- Amazon S3 – Object storage system with industry-leading scalability, data availability, security, and performance
- AWS IAM – Grants permissions to our services to access other services and data
- Amazon Athena – Interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL
- Amazon Redshift Spectrum – Feature within Amazon Web Services‘ Redshift data warehousing service that allows to conduct fast and complex analysis on objects stored on the AWS cloud.
- TBAC – Tag Based Access Control scheme that allows granular permissions control for Lake Formation Data
How it Works
Before understanding how to implement a data mesh, it is important to grasp the structure of the solution and how the different components interact.
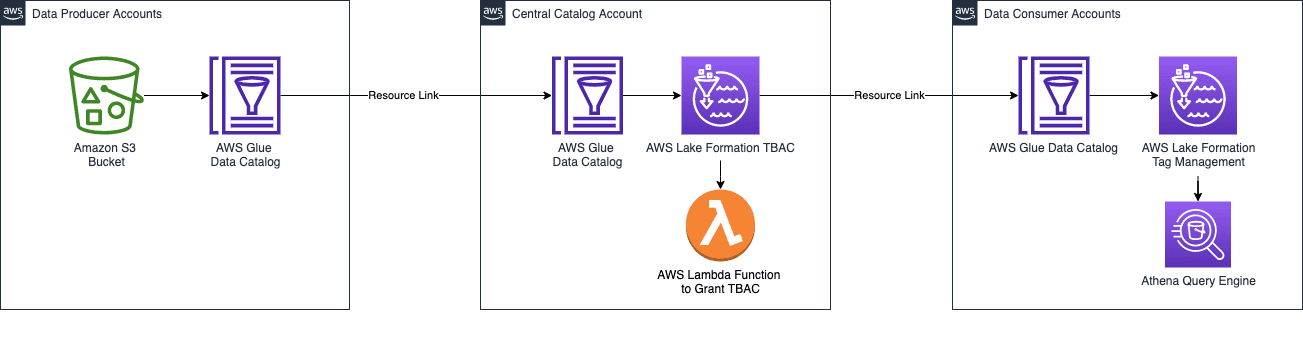
Figure-01
The diagram above is a high-level illustration of a data mesh solution. There are simple producer and consumer accounts as well as a central account that uses AWS Glue to link to data in each. Since both producer and consumer have data links to the central account, this transitive relationship allows the consumer to access the data from the producer without needing direct access to the producer account. You will also notice that tag management is included in producer and consumer accounts to allow for fine-tuned access management.
Now, with the help of the diagram below, let’s look a bit closer.
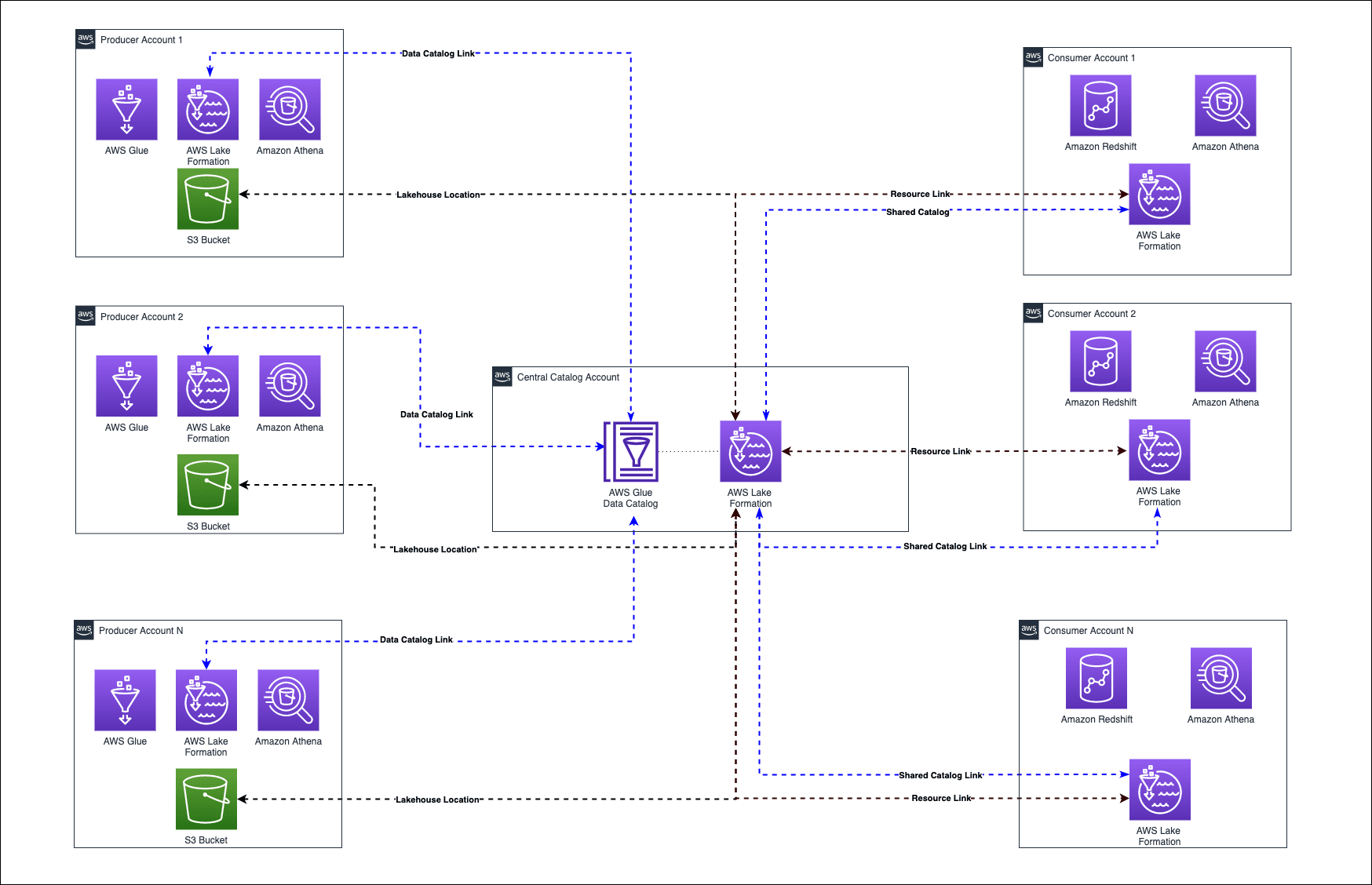
Figure-02
At first glance, we notice that there are many producer and consumer accounts and that they all reference objects in the central catalog. The purpose of this is for both producer accounts and consumer accounts to reference the glue catalog in the central account. These references give the consumer account a “view” into the central account’s AWS Glue catalog and give the central account’s AWS Glue catalog a “view” into the producer account’s data. With these references in place, when a query is issued in a consumer account, it traverses the references through the central account to the data in the producer account. Since AWS Glue caches the data for queries, the performance of this pattern is low-latency and the end-user is not able to notice a difference between accessing data through the data mesh versus directly from an S3 bucket.
To put your data mesh in place, you need to follow the steps below to onboard each producer and consumer accounts. These steps are automated via code as part of the blueprint for this solution.
Producer Account
- Data onboarding: The first step to using any dataset with the data mesh solution is to onboard it. In this example, we are assuming that all the data is already in S3. For more guidance on data ingestion please see our Data Pipelines Foundations.
- Share with Central account: Once the data is prepared in the producer account, the next thing that needs to happen is that the data needs a permission policy attached with it, such as an IAM policy onto an S3 bucket, that shares the data with the central account.
- Create Central Catalog Table: At this point the central account needs to run a Glue Job, Lambda, or Crawler to create a table for the producer data in the central account. We recommend that a Crawler is used to onboard the desired dataset from the producer account.
- Setup TBAC for data: This step requires the team that produces the data to determine tagging standards for the data they are onboarding to the data mesh. At the end of this step, the data that has been onboarded should be tagged according to the team’s tagging standards.
Consumer Account
- Setup TBAC for consumer: All consumers setup with the data mesh system should be able to see (describe) your dataset. Only consumers with access to the specific tags should be able to query it. This is controlled by updating permission grants on an account level from the central account. Each consumer account should be granted permissions with a grant option so that they can delegate these permissions, or a subset of them, down to the analytics users in the consumer accounts.
- Create Consumer Resource Link: Once the consumer account has access to the data through the TBAC system, they will need to create a resource link. This process creates a linked copy of the table in the central account in the consumer account Glue database.
With the producer and consumer accounts onboarded, the organization will have a foundational data mesh implemented and will be ready to customize it to fit their needs. For instance, you can create automated hooks that will kick off the consumer and producer onboarding when requested.
Some other enhancements include leveraging Amazon Athena integrations to standardize ad-hoc queries, Amazon Redshift to perform analysis from a data warehouse, or Amazon SageMaker to run machine learning models against the data set.
Blueprint
The Cloud Development Kit (CDK) application that configures the baseline components discussed above can be found here. Within this repository, you will find the following sub-directories with code to handle automated infrastructure setup for the baseline data mesh implementation.
- Central Account – Create an AWS Glue database, a crawler that can pick up the data from the producer account, and a lambda function to handle TBAC.
- Producer Account – Set up an s3 bucket with sample data, attach a policy to that bucket that allows the central account access, and create a lambda function to generate a resource link back to the producer account.
- Consumer Account – Create an Athena workgroup for accessing the data and a lambda function for creating the resource link for the data tables.
- Ops – Contains a shell script to automatically kick off the deployment of resources to all three accounts above.
Benefits
Faster Data-Driven Architecture – Improves business domain agility, scalability, and speed to value from data. Decentralizes data operations, and provisions data as infrastructure as a service. This reduces the IT backlog and enables business teams to operate independently to focus on the data products relevant to their needs. A data mesh makes data accessible to authorized data consumers in a self-service manner, hiding the underlying data complexities from users.
Strong Governance and Compliance – With the ever-growing number of data sources and formats, data lakes and data warehouses often fail at massive-scale data integration and ingestion. Domain-based data operations, coupled with strict data governance guidelines, promote easier access to fresh, high-quality data. With a data mesh, bulk data dumps into data lakes are outdated.
Simplified data products – The “Data as a Product” idea is a design philosophy that can enhance a company’s ability to make use of their data. Under this paradigm, the consumption and presentation of data occurs along standardized interfaces, so that teams know exactly how and where to get the data they need, and how to make their data available for others to use. This approach is flexible enough to let teams use whatever architecture they prefer internally.
Cross-functional domain teams – As opposed to traditional data architecture approaches, in which highly skilled technical teams are often involved in creating and maintaining data pipelines, data mesh puts the control of the data in the hands of domain experts. With increased IT-business cooperation, domain knowledge is enhanced, and business agility is extended.
Business Unit Autonomy –Provides a method by which organizations can share data across business units. Each domain is responsible for the ingestion, processing, and serving of their data.
End Result
Applying data mesh concepts to a company’s data infrastructure will help it meet goals with scalability, security, compliance, and cost while keeping complexity relatively low. With so many factors to consider when trying to implement a data mesh, our solution provides a reliable starting point that can be customized to meet the needs of any enterprise. The core concepts of shareable data, cataloged centrally, and shared to consumer accounts can be help enterprises across the financial services industry achieve their data management goals.