

About the Customer
The customer is one of the world’s largest rating agencies and has recently acquired data analytics firms from whom it needs to consume massive volumes of risk analytics data to establish a new level of business providing environmental, social, governance, and climate risk products to clients downstream.
Key Challenge/Problem Statement
The customer was working on the first release of their new big data pipeline and data warehouse product. It would ingest, process, and store millions of records each month and provide this data to multiple end-user applications, including dashboards, data marts, and data analytics platforms. The system was expected to grow to many billions of records processed from hundreds of different data sources and transformed in as many different ways. The customer rightly decided that manual testers could not execute the thousands of tests necessary to ensure their desired level of quality before each release.
State of Customer’s Business Prior to Engagement
The customer had no alternative to manual QA processes prior. Testing engineers manually verified and loaded batches of example input files into a QA application environment once the development team thought the application was ready. Manual QA would find and report bugs in Jira tickets, and developers would fix those bugs. By the time the same bugs were ready to be re-tested by QA engineers, days had passed, and it took on average 1 hour for manual QA to test a single dataset of the initial 27 input files, which meant that full regression tests took so long that they simply could not be performed before each release.
Proposed Solution & Architecture
Vertical Relevance helped the customer create a big data pipeline that ingests large environmental, social, governance, and climate risk data files and transforms them into highly normalized, partitioned, efficient AWS Glue table structures stored in S3. The curated output data can then be queried with various AWS tools and consumed by downstream applications. The pipeline incorporated important functionalities to increase speed and automation with automated triggers and workflow management. The following diagram is a simplified view of the data pipeline architecture.
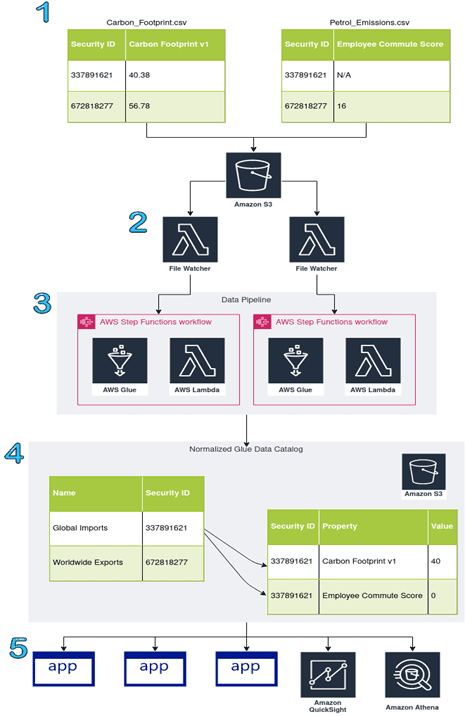
Figure-01
- In step 1, wide (unstacked) format, input CSVs are loaded into the landing S3 bucket.
- Lambda functions are triggered when data is loaded in the landing S3 bucket to invoke a parallel execution of the automated data pipeline using each file.
- Data checks run against each file using ETL logic in Glue and passing files are loaded into the Glue Data Catalog. The data pipeline workflow is managed with Step Functions.
- Data is stored in S3 in the Parquet format. If all goes well, the data values match the CSV but are instead stored in long (stacked) format.
- Downstream tools and applications consume the curated data in S3 for analysis, visualization, and further ETL.
In addition, Vertical Relevance assisted with building an automated testing framework to verify the behavior of this pipeline. The customer left the choice of testing strategy and tooling up to Vertical Relevance, so long as it satisfied the requirement to speed up testing cycles. Vertical Relevance’s early analysis uncovered additional requirements for the testing framework. Vertical Relevance concluded that the proposed testing framework solution had to meet the following requirements:
- Improve the speed of the current testing cycle considerably
- Be scalable, in both speed and maintainability, to thousands of tests
- Provide production readiness information to high-level business stakeholders
Since the testing framework was meant to provide releasability feedback to business stakeholders, Vertical Relevance recognized that a unit testing framework would not be sufficient, since those types of tests inform developers rather than business leaders. The tests had to provide verification of the system as a whole, and they had to report results in a way the business could understand.
Vertical Relevance chose to design and implement an automated Acceptance Testing stage using Behavior Driven Development (BDD) methods.
In the spirit of BDD techniques, Vertical Relevance collaborated directly with the Senior Vice President, VP of Data Architecture & Strategy, VP of Project Management, VP of Infrastructure, and DataOps engineers to create non-technical test case definitions that double as executable application requirements. These defined how the business wanted the pipeline to behave from the end user’s perspective. In this particular system, end users are those who put data into the landing S3 bucket and then consume the data downstream.
Vertical Relevance built the testing framework using the Python pytest testing library and two main pytest plugins, pytest-bdd for BDD implementation and pytest-xdist for parallel test execution. Like other BDD frameworks, pytest-bdd defines test cases as scenarios in a Given, When, Then format (using a language called Gherkin) in files called feature files. Below is an example of a test case Vertical Relevance developed with the customer:

The tests were designed in a highly scalable manner so that new cases could be added without writing code, saving the business time to implement tests in addition to the improvements over manual test execution time.
Test cases were first implemented to deliver the greatest benefit for the smallest development time investment. To this end, Vertical Relevance sought to find a quick path to checking the system’s actual behavior against its expected, correct behavior. The customer’s trusted manual QA had previously validated several datasets as being valid or invalid, therefore adopted files were the canonical test data, referring to them as “known good” and “known bad” files, respectively. By asserting that the pipeline reported a success status for known good files and a failure status for known bad files, the first tests quickly performed simple smoke-style regression tests to provide immediate feedback on the releasability of the product. This was a good start, but it was far from sufficient.
Once tests were in place to check the pipeline’s reported statuses for various files, Vertical Relevance designed and implemented tests that exhaustively compared the integrity of input data vs output data, which precisely highlighted any piece of data that was transformed incorrectly.
Vertical Relevance reduced the amount of time required to verify the correct transformation of the data from an average of 1 hour per dataset to approximately 20 minutes per dataset. For the 27 datasets, this translated to a reduction from 27 hours of tester time to 9 hours of compute time. Crucially, these tests were run in parallel for all 27 datasets. The automated tests run on one small Jenkins worker pod on Amazon EKS, whereas accomplishing the same volume of parallel execution with manual testers would have required the customer to pay 27 testers. When the number of tests greatly increases, pytest-xdist can support distributed test execution across more Jenkins workers.
Besides improving execution speed over manual testing, Vertical Relevance automated the process of reporting defects by producing differential CSVs showing the precise differences between input and output datasets. For tests that verified the integrity of data, Vertical Relevance used Athena to collect the output data from the Glue Catalog using SQL, then used Pandas (a Python data analysis package that is popular with DataOps and data scientists) to re-shape the Glue Catalog/Athena data back into the same format as the input CSV. The tests then load the input CSV into Pandas as well and compare the two Pandas objects to check whether they are identical. If they are not identical, the tests publish to S3 a new CSV that details, cell-by-cell, each difference between the input data and output data. This CSV can be opened in Excel and allows a quick diagnosis of the application’s failure. Cells that match between the two files are excluded from this diff, reducing the size and increasing the usefulness of the output.
Below is an illustration of this testing and reporting process. The data pipeline has been represented as a single pipe icon to simplify the diagram:
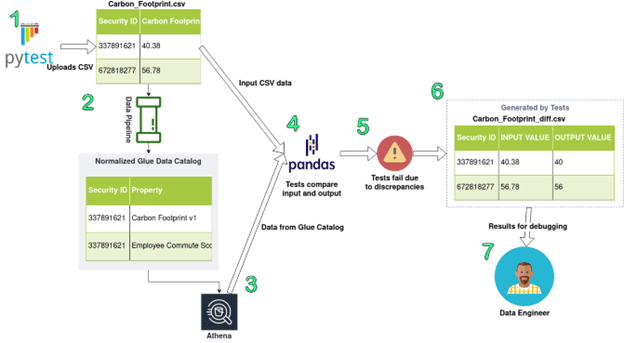
Figure-02
- Pytest uploads a test CSV. It is a known-good file, which means the tests should pass if the pipeline is working correctly.
- The data pipeline processes the tests. This usually takes 15-20 minutes.
- The tests query Athena for the results of the pipeline run.
- Pandas transforms the Athena output data into the same format as the input data and compares the input data to the re-shaped output data.
- The tests fail because they detect discrepancies between the input and output Carbon Footprint columns. In this example, the data type of this metric has been incorrectly coerced from a floating point value into an integer.
- The tests produce a new CSV showing only values that differ between the input and output.
- A data engineer analyzes the differential CSV to debug and fix the responsible defect.
The major difference between the above diagram and the real solution is, of course, the size of data. When the input and output both have millions of records, generating a report of only the differing values in a matter of seconds obviously has major advantages over manual spot checking or assuming the data matches.
Finally, Vertical Relevance provided documentation and training for the QA engineers and developers who were taking over the project.
AWS Services Used
AWS Infrastructure Scripting – CloudFormation, boto3
AWS Compute Services – EKS, Lambda, Step Functions
AWS Storage Services – S3
AWS Database Services – DynamoDB
AWS Analytics Services – Glue, Athena
AWS Management and Governance Services – CloudWatch, CloudTrail
AWS Security, Identity, Compliance Services – IAM, AWS Single Sign-On
Third-party applications or solutions used
- pytest, pytest-bdd, and pytest-xdist
- Pandas
- Jenkins
- Kubernetes
Outcome Metrics
- Automated data pipeline workflow to create curated views for end user consumption – eliminated manual data processing
- Reduction from 1 hour average testing time per dataset to 15-20 minutes for the entire dataset
- Reduction in cumulative average regression test suite time from 27 hours to 40 minutes, a 4000% decrease
- Capability to increase acceptance testing frequency from once per 2 weeks to multiple times per day
Summary
By engaging with Vertical Relevance, the customer obtained a carefully planned, scalable, and maintainable testing framework that dramatically reduced testing time for their mission-critical application and enabled them to constantly test the application’s releasability. Vertical Relevance consultants took a business-focused approach rather than ladening the customer with technology aimed at developers only. While it will also improve developers’ lives, Vertical Relevance’s work will help improve the customer’s overall business outcomes by getting them to market faster, more safely, and more confidently.