

Overview
Financial Services Institutions must deliver world class digital experiences with high reliability to be competitive. They must also deliver new capabilities regularly to stay competitive in an increasingly competitive market. The user experience of their digital platform must be second to none to ensure they attract and retain customers who have a high standard based on experiences from other online industries. Using dated and monolithic on-premises technology weighs down and slows your product team from achieving these outcomes, while smaller more nimble financial technology firms seem to move quicker and capture market share.
The challenge is how do you refocus your time and energy to deliver new and ongoing Digital value for your customers and grow your business?
The prospect of taking on a modernization program for your most business-critical systems is a daunting task for any team that is not already familiar with AWS and modernizing complex platforms. Many times, older solution implementations have grown to be unwieldy and costly as scaling the capability for key functions in the solution means scaling the entire solution.
Vertical Relevance’s Monolith to Microservices Foundation provides a proven framework on how to break the monolith and deliver improved agility to increase the pace of innovation and drive value to your customers and your business. In addition to this our customers often experience improved platform performance and customer experience, improved solution reliability, improved system observability, all resulting in a significantly improved competitive edge.
Prescriptive Guidance
Before diving into breaking the monolith, it is important to understand some of its core concepts. Since applications can be very complex, understanding the considerations, approach to evaluate the scopes and priorities of work you want to take on, and then how to manage the work is key to structuring the program for success.
Definitions & Concepts
- Monolith – When the code of an entire application resides in a single codebase, and that code is deployed as one large chunk, to the same group of servers, it’s known as a monolith. On the one hand, the entire application is in one place and is easy to account for, and easy to monitor. On the other hand, the resources allocated to an application are measured and scaled by a composite of all the functions being performed. This can lead to unnecessary resource costs, especially if a small number of heavy-load services dictates the capacity for many infrequently called services.
- Strangler Fig Pattern – Martin Fowler wrote about the approach that guides this approach back in 2004 and it has been tested thoroughly as a basis for solution modernization. This pattern takes an existing service from a monolith and decouples it to a standalone microservice. Application calls that were made to the legacy service are pointed to the new service, until the old service is “strangled” and no longer has clients. This pattern is designed to have both services running in parallel, so that clients can switch from old to new as their deployment cycle allows.
- Bounded Context – A grouping of models (information and functions) within a system that make logical sense and the deliberate boundaries of that group of models that make sense to keep together, for the consistent and whole purpose of the functionality exposed to other parts of the system outside the bounded context.
- Application Programing Interface (API) – Commonly a URL pattern with a defined payload, this is the interface contract which the application will behave.
- Event Interface – Commonly an event pattern with a defined payload and interface, this is the interface contract which the application will behave.
- Context-Based Router – RoutesAPI requests or events to the appropriate URL endpoint or event subscriber based on the data contained in the API request or event.
- Platform – The overall solution targeted for modernization. It may be comprised of one or many applications, each of which may contain one or many bounded contexts.
- FMEA – Failure Mode & Effect Analysis. Analyzing possible failure situations in your architecture design and operations and how to test the technical solutions, your observability solutions and how your teams respond. Once defined, run game days to run the simulations and evaluate how successfully the system responds, observability solutions successfully monitor the issues that occurred and how your teams respond.
- RTO – Recovery Time Objective – the amount of time after a failure the solution becomes available again to the level of normal operation.
- RPO – Recovery Point Objective – the amount of data loss your solution can tolerate before negatively impacting your business.
Design Principals / Best Practices
With any monolith, it can be daunting to know where to start and how to tackle the work involved with modernizing and migrating into a more manageable solution. Vertical Relevance recommends the following approach to define your approach and then manage the successful delivery of your program to achieve the outcomes of increased agility & innovation:
Identify your business goals and how you measure success
As you begin your journey to decompose your monolith(s) and deliver improved agility & innovation you need to ensure you have a small set of clear business goals and metrics by which you will evaluate achieving those goals. You should ensure all of your team members and management understand the definition of the goals and how success will be measured. You should then baseline your performance against those metrics before the start of your work.
Your goals and metrics should be specific to the business outcomes you need to achieve, but Vertical Relevance recommends you consider some of the following goals and metrics:
- Solution deployment density – number of solutions deployed on a single server or logical environment. Lowering these drives breaking the monolith and making services independent
- Service interface density – number of functional or event interfaces contained in a service. Lowering these drives breaking the monolith and making services independent
- Platform experience – both system reliability and transaction performance. Improving these drives improvement in customer experience
- Lead time for change – speed of delivery of changes through your environments. Lowering these drives your team agility through lowering the time taken to make changes through your solution delivery lifecycle and drives an increase in the volume of innovation.
- Change failure rate – quality of the delivery of changes into production. Lowering these improves agility by focusing on making the right change the first time and lowering re-work needed that slows down the team, enabling more innovation to occur.
- Mean time to recover – speed of recovery when an issue occurs. Lowering these improves the team’s speed to recover from issues and keep the focus on innovation.
Evaluate your platform & prioritize your iterations into a roadmap
When you begin to evaluate your platform, you may find you have one large monolith, or you may find out you have multiple monoliths. If you are addressing multiple monoliths, then prioritize which to address based on:
- The number of critical business functions that are processed by the monolith
- Solution interface density
- Solution deployment density
- Platform experience improvements needed
When you are focused on a single monolith, or have prioritized across your multiple monoliths, then within each monolith:
- Decompose the monolith into bounded contexts
- Evaluate each bounded context with the above metrics to identify the priority across the bounded contexts
Generate your complete backlog for all bounded contexts you identify, i.e., what you perceive as the right groupings of logical functionality that you will address to get to the future state of non-monolith solutions running on AWS.
Size each bounded context in your backlog by using an existing comparative sizing mechanism that works for your teams. Then prioritize the backlog by scoring each bounded context with the metrics you use above coupled with the size of the effort to deliver the work.
It is recommended you start with a bounded context that may be considered a simple example, so the team can learn how to deliver this work and can apply learnings to each bounded context they take on from the backlog.
Iterate on your bounded contexts until complete
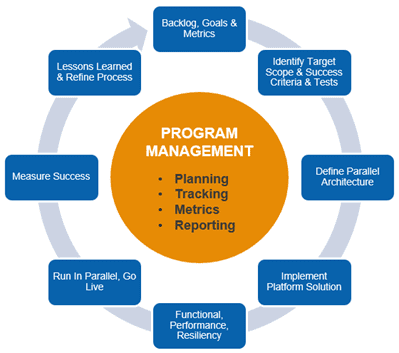
Figure-01
For each bounded context:
- Backlog, Goals & metrics – Evaluate the business value and risk of all business processes/workflows in the backlog of scope for migration to AWS, and how we define success for each and the overall program through agreed business goals and metrics
- Initial Target Scope & Success Criteria & Tests – Identify a small low risk target with a well-defined bounded context to prove the migration process, targeting the design, implementation, testing of performance and resiliency, DevOps implementation, and go live of the target. Develop functional automated tests for the current solution to enable comparison to the target solution
- Define Parallel Architecture – Define the architecture of the target scope to enable it being triggered and running in parallel for testing and verification into a target datastore that is not the live system – allows validation of workflow and re-use of existing testing mechanisms if they exist
- Ensure same interface is used into the new design, with the new interface subscribing to the API interface or process events/messages and run the new process in parallel
- Use context-based routing to ensure the requests/events are routed to the right target
- Either containerize the application services or implement them in cloud native functions, identify target data store designs, performance and scalability designs based on demand patterns, architect observability solutions, perform FMEA and define targeted resiliency scenarios and disaster recovery approaches
- For all components involved identify the appropriate approach to re-host, re-platform or refactor into cloud native solutions
- Confirm authentication, authorization, and user identity management approach and whether user migration is needed, or an existing user identify solution will be used
- Synchronize data back to the original solution data store to allow the legacy functions to operate successfully until no longer needed
- Implement Platform Solution – Implement DevOps pipelines to build out the SDLC environments, incorporating security and compliance, and observability to deliver the target scope
- Functional, Performance, Resiliency – Test the workflow in parallel, run performance tests, run resiliency tests for high risk and medium risk failure scenarios, run disaster recovery testing – ensuring at least meeting existing baselines if not improving them in performance, RTO and RPO
- Run In Parallel, Go Live – Run in parallel in production to validate functionality, performance, and train teams supporting the system
- If user migration is a dependency, migrate users into the new solution and validate all roles operate successfully
- Run game days deliberately failing over the test system to confirm successful observation and management
- When ready switch into new architecture, validate it and fail back if any issues occur during active monitoring of the solution
- Measure Success – Measure the effectiveness of the delivery through the definition of success for the delivery of the target scope
- Lessons Learned & Refine Process – Gather lessons learned of the process and refine process to improve
- Program Management – Plan the next wave of work with the next defined target scope, execute and repeat and continually improve from lessons learned with each iteration
- Extrapolate the program timeline and resources needed and refine
- Track the program of migration of prioritized functionalities in waves with metrics defined from the definition of program success
- Repeat – Repeat the approach above with scaled teams (if needed) executing the same approach with well-known solution and architecture dependencies
- Original Solution Dependencies Removed – Ensure all dependencies to the original on premises solution are removed, enabling the new modernized microservice solution to operate independently. Once this is done stop data synchronization back to the original solution data store
Strangling The Monolith
When breaking up the monolith or monoliths in your platform, we recommend following the Strangler Fig Pattern. To do so you decompose the monolith into bounded contexts, and prioritize the order in which you will address them into a backlog.
The steps to decouple an existing function within a monolith into a standalone microservice are:
- Write tests
- Decouple data
- Expose the API
- Sync data changes
Application calls that were made to the legacy service are pointed to the new service, until the old service is “strangled” and is no longer used. This approach is designed to have both the new and the legacy services running in parallel to allow parallel testing and switch from the legacy to the new as their deployment cycle allows.
Components
- API Gateway – The API layer that handles the client connections and routing – our context-based router
- Lambda – executes the logic in the API call
- DynamoDB – stores our bounded context data
- DynamoDB Streams – publishes data storage events as data is updated in the decoupled service
- Stream Processor – subscribes to data events and keeps the monolith data store in sync
How it works
Candidates for the Strangler Fig Pattern are services used by the application that are separated into a logic grouping, or a bounded context. For example, a web-based solution may have database tables for Customers and Orders. As part of a business process, a zip code validator checks the customer’s zip code against a table in the application database. The zip code may be used heavily by the application, but the application does not own the data. It may even be updated by an external system. We’ll use this as an example to split off into its own microservice.
1) Write Tests: The best way to define the requirements of the new service, is to write tests that can be executed against the existing service. This gives us a clear set of use cases to apply to the new service and applies a measurable level of confidence to refactoring and deployment. The new service will be complete when it can pass all the same tests as the production service.
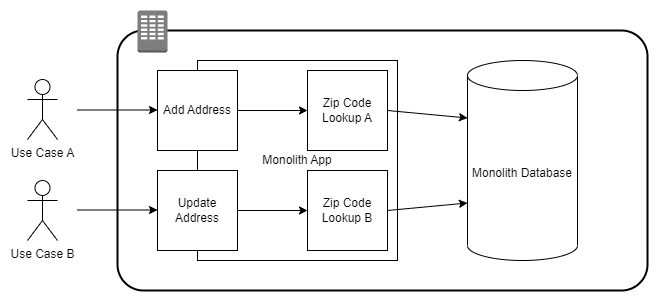
Figure-02
The following is the architecture for the monolith we deploy in AWS as the starting point for the example in this solution. We do this because we do not have a datacenter we can deploy the monolith into. The architecture is the equivalent of a simple on-premises architecture using EC2 to host the application, with a load balancer in front of it and accessing a relational database.
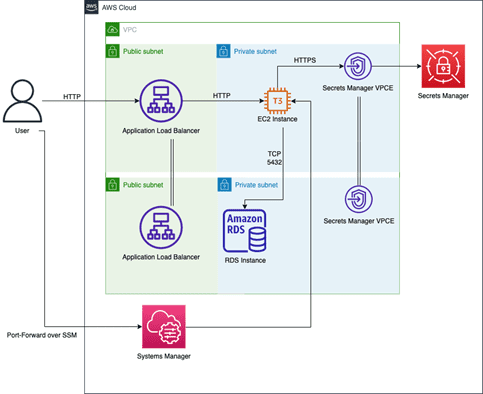
Figure-03
2) Decouple Data & Expose the API: As the data will be in its own bounded context, and it will have a different access point than the main application, we can copy it from the monolith database and create a DynamoDB table that will be owned by the microservice. We leave the monolith copy of the data in place because there will be legacy calls to the data that are not immediately migrating, and they need to remain functional. All access to the data in the new service will only be accessible via an API. IAM permissions will be set on DynamoDB to only allow data access from API methods. A contract should be published defining what methods can be called and the properties of the request and response object schemas.
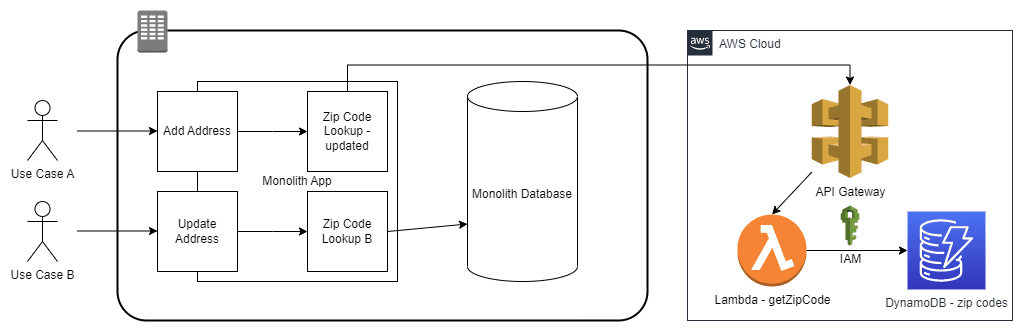
Figure-04
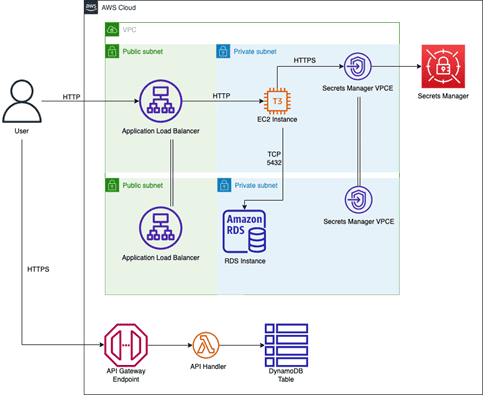
Figure-05
3) Sync data changes: The legacy system still needs access to the data from the legacy tables, but our new DynamoDB table has become the system of record. Utilizing DynamoDB Streams, which publishes events when data is changed, we can create a subscriber that passes those changes along to the legacy table.
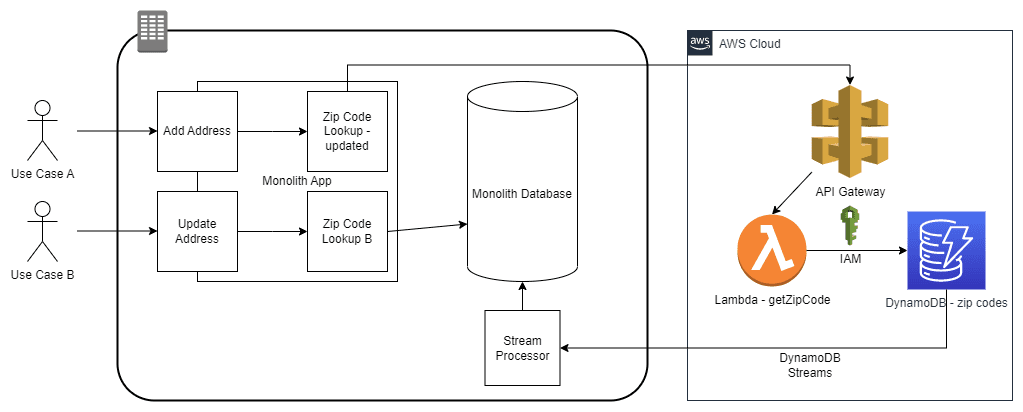
Figure-06
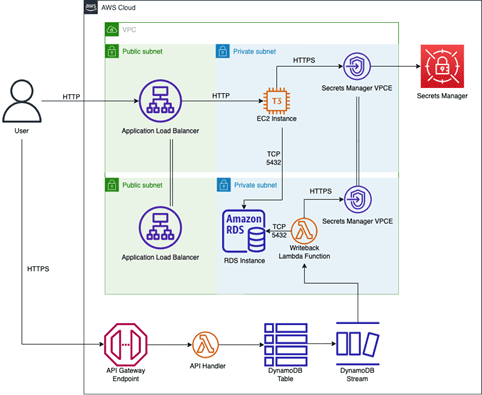
Figure-07
Blueprint
The blueprint provides step-by-step instructions on how to deploy the monolith application, the microservice using API Gateway/Lambda/DynamoDB, and the stream processor/writeback function. This works through the steps to iterate a function through the Strangler Fig pattern. The blueprint uses a Makefile to automatically set up the prerequisites, deploy the solution using the CDK, and hydrate the databases.
- Deploy Infrastructure – The first step in the blueprint is to deploy infrastructure that mimics the monolith application into AWS. The monolith is deployed, zip code addresses are hydrated into the database, and the monolith is validated to be operating correctly by querying the monolith API to retrieve the address associated with a test zip code.
- Deploy Microservice – The second step of the blueprint is to deploy the microservice, hydrate the zip code addresses into the DynamoDB table and validate it works by querying the microservice and retrieving the address for the test zip code.
- Deploy Data Sync Function – The third and final step of the blueprint is to deploy the stream processor/writeback function and validate it works. It is validated by sending an update to the zip code address to the microservice and seeing it propagate to the monolith database by querying the monolith API.
Benefits
- Increased competitive edge through agility – implement shorter cycle times to deliver work so you can iterate faster and respond to change in your market quicker, enabling a significant competitive edge
- Improved performance – decompose the monolith solution, minimize the latency, right size compute, and implement effective caching throughout your architecture to improve the performance of your Digital Platform across the experience
- Improved reliability – implement event driven microservices that detect and automatically scale up and down on demand to ensure a reliable Digital Platform that is always there when your customers need it
End Result
Vertical Relevance’s Monolith to Microservices Foundation provides a proven framework on how to break the monolith and deliver improved agility to increase the pace of innovation and drive value to your customers and your business. By following the approaches laid out in this Foundation, customers will manage risk and lay out a consistent iterative approach to decompose the monolith into cloud native microservices, following a well-defined process.