

Problem Statement & Introduction
Disaster recovery looks different in regulated environments. A regional outage is not just an availability event. It can quickly become a reporting issue, a service-continuity issue, and eventually a compliance issue. That changes the way teams need to think about failover. The process cannot live only in a runbook. It has to be executable, tested, and controlled.
A common pattern is easy to recognize: production runs in one primary Region, and failover depends on multiple people. The process usually crosses application teams, SRE, networking, security, and third-party data platform owners. Streaming, workflow orchestration, analytics, and reporting services may all have their own recovery steps. None of that is easy to coordinate during an actual outage. Recovery time objectives under this model can stretch to twelve hours or more and reflect processes that have been mapped out but never actually run end-to-end.
Fragmentation makes the problem worse. One platform may replicate data. Another may support a limited failover action. A third may require a manual ticket or console change. The result is not really a failover process. It is a collection of disconnected recovery tasks that someone has to sequence correctly under pressure. There is no single place to execute the failover and recovery means a cascade of manual steps across teams, with no enforced sequence and significant room for error.
Many organizations reach this point and take risks. The architecture that was originally intended to enable scale was not designed with regional failover in mind, and retrofitting it is expensive, especially when every application team builds its own approach. Script-heavy DIY solutions tend to be brittle and inconsistent: each team builds something slightly different, failover procedures are rarely tested, and the burden of keeping topology and routing rules in sync grows quickly as the environment scales.
This post covers what we built to address those problems: a combination of Amazon Application Recovery Controller (ARC) Region Switch and a GenAI-powered migration utility that automates the most time-intensive parts of onboarding applications for multi-region failover.
Below are challenges we often see across many organizations:
| Problem | Details |
| Single-Region Dependency | All production workloads in one AWS Region, with no mechanism for traffic failover beyond a manual all-hands process. |
| 12+ Hour RTO | Estimated recovery time based on a failover process that has been mapped but never run. Manual coordination required across internal teams and third-party managed services. |
| Regulatory Reporting Risk | State-level regulations require timely report generation. Any extended outage risks non-compliance and the penalties that come with it. |
| Fragmented DR Capabilities | Individual solutions with inconsistent behavior: some offer data-plane replication only, others have limited failover without control-plane coordination. |
| No Orchestration Layer | No single mechanism to sequence failover across workloads. Each application must be handled independently, manually, in an already stressful incident. |
| No Reusable Pattern | Even if one team solves it well, there is no shared module or template other teams can adopt. Every application becomes its own project. |
Background: What ARC Region Switch Is and Is Not
The Amazon Application Recovery Controller (ARC) service is built around the idea that traffic routing decisions during an outage should be deliberate, sequenced, and observable rather than improvised. It provides routing controls, readiness checks, and structured workflows for multi-region recovery. What it does not do is replicate your data or make a poorly designed application stateless; the architecture must still be designed for resilience. ARC provides the control plane to act on it.
The Region Switch capability within ARC is what orchestrates the actual traffic movement. Below are core components of the solution:
Routing Control: A logical switch within ARC that can be toggled ON or OFF to direct traffic to or away from a specific Region. Routing controls connect to Route 53 health checks, so a state change has an immediate and deterministic effect on DNS resolution.
Route 53 Health Check (Endpoint / RECOVERY_CONTROL / Calculated): ARC relies on layered health checks. Endpoint checks monitor whether an application is actually responding. RECOVERY_CONTROL checks reflect the state of a routing control. Calculated health checks combine both signals using a threshold rule (for example, HealthThreshold=2) so that traffic only goes to a Region that is both technically healthy and administratively open.
Region Switch Plan: A structured execution plan that defines the exact sequence of steps to move traffic between Regions: routing control updates, scaling actions for Auto Scaling groups, EKS, ECS, and Aurora Global Database, manual approval gates, and custom Lambda blocks for integrations like ticketing systems or configuration flags.
Safety Rule: A guardrail that prevents routing control changes that would violate a defined condition. The most common pattern: an ATLEAST rule that ensures at least one Region is always receiving traffic, so an operator cannot accidentally disable both Regions simultaneously under pressure.
The important distinction between ARC and a custom failover script is that every ARC routing control change goes through a durable API with built-in audit logging, and every Region Switch plan execution is observable and reproducible. That difference matters significantly when an organization must demonstrate to a regulator that its DR process is documented, tested, and controlled.
Solution: Building the ARC Foundation and Accelerating Onboarding with GenAI
Through experience, we’ve learned that the path to multi-region readiness was not simply turning on ARC itself, but rather it was getting the surrounding pieces (DNS, ownership, approval paths, health checks, etc) to behave and operate like one system. It often requires alignment across architecture, infrastructure-as-code, operations practices, and incident response. In practice, the starting point for most organizations is a large and varied IaC estate: CloudFormation in some accounts, Terraform in others, CDK in a few, and Kubernetes ingress definitions scattered across the data platform. Getting each application onboarded to ARC the traditional way (manually one at a time) is not a realistic path at scale.
The solution we built combines two layers: a standardized ARC and Route 53 foundation shared across the organization, and a GenAI-powered migration utility built to accelerate onboarding by analyzing existing IaC and generating ARC templates.
Layer 1: The ARC and Route 53 Foundation
The ARC cluster is provisioned in a centralized cloud platform or tooling account, shared across all accounts in the AWS organization using AWS Resource Access Manager (RAM). In this configuration, routing control state changes happen from a single, auditable location rather than being scattered across individual application accounts. The SRE team owns that account and holds IAM-controlled access to modify routing control states.
From there, Terraform modules, often called golden path modules, encapsulate the standard ARC configuration for a given application. This includes routing controls for the primary and secondary Regions, endpoint and RECOVERY_CONTROL health checks, calculated health checks combining both signals at HealthThreshold=2, and Route 53 failover records (CNAME or Alias A depending on the endpoint type) attached to those calculated checks. Any team in the organization can consume those modules without having to understand the full ARC architecture. That is what makes the pattern scale.
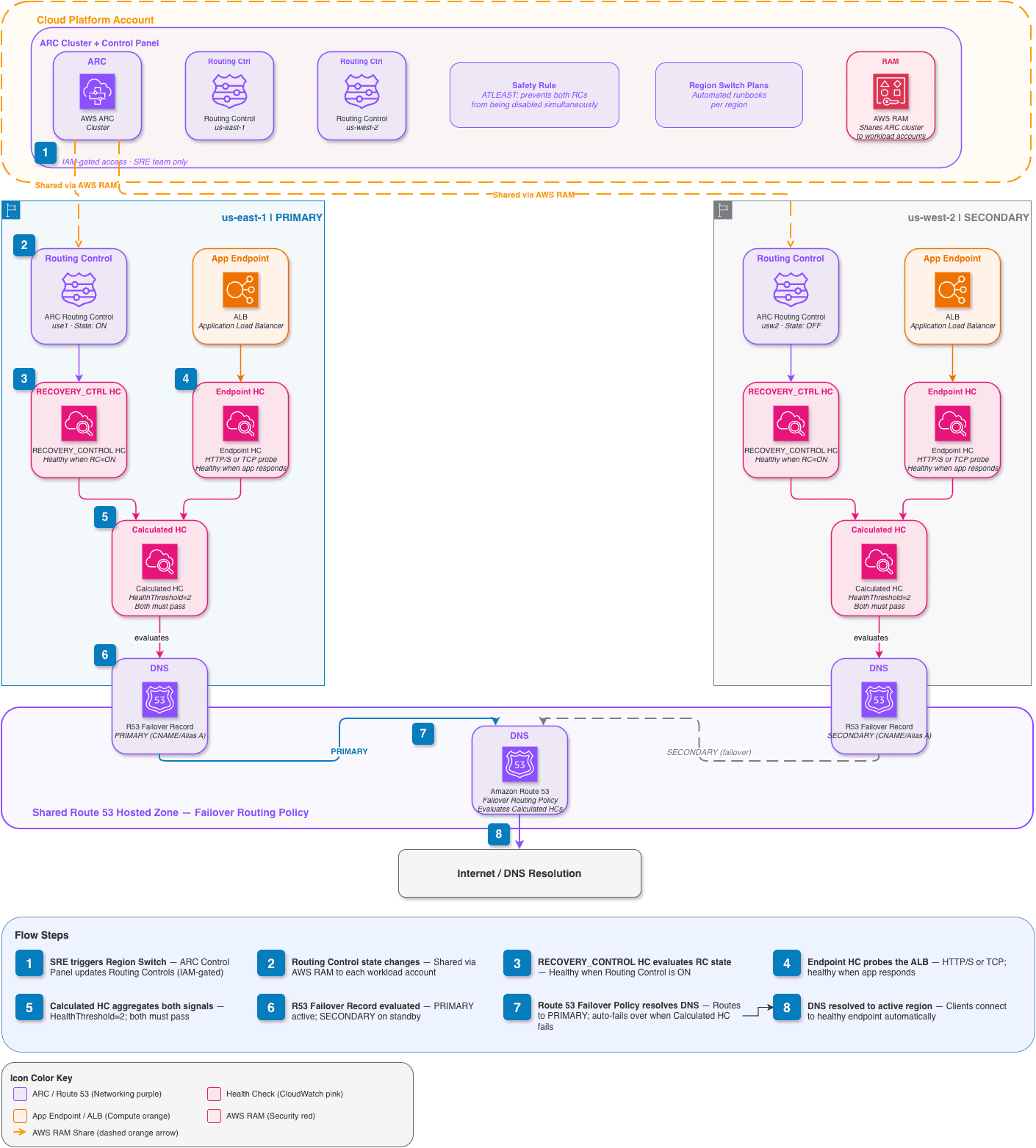
Figure-01
The routing and health-check logic lives in its own dedicated Terraform state, separate from individual application stacks. That separation means the SRE team can adjust routing configuration without touching an application release, and an application team deploying a new version does not accidentally alter failover behavior. Those two concerns get coupled easily when failover logic lives inside application stacks and separating them removes that risk.
Layer 2: The GenAI-Based ARC Migrator
We built the migrator because we realized that manual processes do not scale. For one application, an engineer might need to inspect Terraform, CloudFormation, CDK, Route 53 records, load balancer outputs, API Gateway endpoints, and sometimes Kubernetes ingress definitions before even drafting the ARC configuration. This can be cumbersome to create for one application, let alone dozens of applications.
The migrator utility is written in Python. It recursively scans the target repository and, optionally, queries live AWS APIs to extract candidate endpoints, hosted zone IDs, record names, and routing-related hints from the codebase. It can identify CloudFormation outputs exposing load balancer DNS names, API Gateway endpoints, and CloudFront distributions, as well as existing Route 53 records and health check configurations. When static analysis is not enough, the live API discovery fills in the gaps.
From those findings, the migrator builds a retrieval-augmented prompt: it selects the most relevant code snippets, combines them with reference ARC templates and example Region Switch plans, and sends the result to AWS Bedrock. Bedrock returns a proposed ARC CloudFormation template and a Region Switch plan definition, including execution blocks for routing control updates, health-check validation, Auto Scaling and EKS/ECS scaling, Aurora Global Database actions, manual approval gates, and custom Lambda blocks.
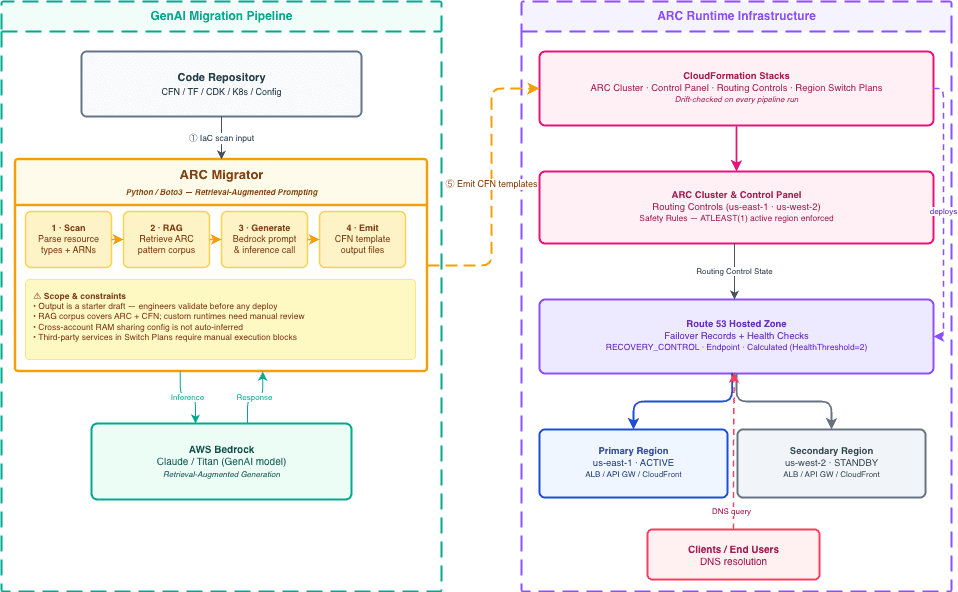
Figure-02
The model does not have context about the organization’s networking conventions, DNS naming standards, logging requirements, or security policies. Therefore, the generated templates are a starting point that the engineering team reviews and refines before anything gets deployed. Additional tweaks and tuning are needed for things like health check intervals, the choice between CNAME and Alias A records, and which endpoints actually matter for a given application’s traffic pattern. That tuning is a critical step to the functionality of the solution and is required before implementation.
Compliance and Risk Mitigation in Practice
Organizations running environments without structured DR in place tend to leave their disaster recovery capability undocumented and untested. This can wreak havoc. In the event of an outage, the SRE team works from a runbook that has never been executed, coordinating across teams managing services with different failover behaviors: some automated, some manual, some not designed for regional failover at all. Recovery time estimates of up to 12 hours assume everything goes well.
ARC can positively change the outcome of an audit. First, every routing control state change goes through ARC’s API and is logged. There is an audit trail of who changed what and when, which is exactly what a regulator asks for. Second, IAM controls who can execute routing control changes. In this case, the SRE team holds those permissions but the application teams do not. That is separation of duties enforced not just by policy but at the infrastructure level. Third, the Region Switch plan enforces execution sequence. For organizations running complex data platform ecosystems, that sequencing matters because third-party services need to fail over in a specific order to avoid data inconsistency. The plan defines that sequence which means the SRE team does not have to remember it under pressure.
We also recommend integrating CloudWatch health check metrics with SNS and Slack notifications. The SRE team gets alerted when a health check degrades before Route 53 has made a failover decision, which gives them time to assess whether to initiate a controlled Region switch or wait for the issue to resolve. That early warning loop is one of the more significant parts of the implementation. It shifts the SRE team from reactive to proactive when it comes time to execute.
In practice, automated failover runs in minutes. The twelve-hour estimate had reflected a process that was mapped but never actually executed end-to-end. Equally important is what this makes possible operationally: organizations running purely manual DR runbooks often have never completed a full failover test. With Region Switch plans in place, a controlled game day becomes a routine exercise rather than a risky operation.
| Problem | Solution | AWS Service |
| Single-Region Dependency | ARC routing controls and Route 53 failover records route traffic across two Regions by design, not by exception. | Amazon ARC, Amazon Route 53 |
| 12+ Hour Manual RTO | ARC Region Switch plans define every failover step in an executable, sequenced plan. Automated failover runs in minutes. | Amazon ARC, AWS Lambda |
| Regulatory Reporting Risk | IAM-gated routing control changes provide a full audit trail. Plan-enforced sequencing ensures third-party services fail over in the correct order. | Amazon ARC, IAM, Amazon SNS, CloudWatch |
| Fragmented DR Capabilities | Golden path Terraform modules encapsulate the full ARC configuration. Any team can onboard without rebuilding the pattern from scratch. | AWS CloudFormation, Terraform, AWS RAM |
| No Orchestration Layer | ARC cluster shared across all accounts via RAM. Single control point for routing state changes, owned by the SRE team. | Amazon ARC, AWS RAM |
| No Reusable Pattern | GenAI migrator analyzes existing IaC and generates ARC templates per application, cutting onboarding from days to hours. | AWS Bedrock, Python |
A Common Implementation Gap Worth Knowing
The ARC foundation and the GenAI migrator together cover a large portion of what is needed for cloud-native workloads and API-based services. Specifically, these are applications where routing controls and Route 53 failover records are sufficient. What this pattern does not automatically address is the set of applications that involve patterns requiring user access through VPN clients and corporate endpoints.
For those applications, a Region switch is not just a DNS change. It may also require updates to VPN client configurations or local DNS settings on user devices, which are managed by enterprise networking teams that sit outside the typical SRE and cloud platform organization. If those teams are not part of the DR scoping conversation from the start, the failover will be incomplete for any application with that dependency, regardless of how well the cloud-side routing is configured.
ARC handles the cloud control plane. What it does not do is solve for everything between the user and the cloud. If your applications have dependencies on corporate networking infrastructure, map those dependencies early and make sure the teams who own them are included in the Region Switch plan design.
Code Example
The following CloudFormation snippet shows the ARC foundation stack: cluster, control panel, routing controls, and the safety rule. This is the shared infrastructure the GenAI migrator references when generating application-specific templates. In practice this is often wrapped in Terraform using the same underlying resource types, but the CloudFormation representation below illustrates the structure clearly.
AWSTemplateFormatVersion: '2010-09-09'
Description: ARC Region Switch Foundation - Cluster, Control Panel, Routing Controls
Parameters:
Environment:
Type: String
Default: prod
Description: Environment name used to namespace ARC resources
Resources:
# ARC Cluster - one per environment; all five ARC cluster endpoints are
# provisioned automatically for high availability across AZs
ARCCluster:
Type: AWS::Route53RecoveryControl::Cluster
Properties:
Name: !Sub "${Environment}-arc-cluster"
# Control Panel - logical namespace for routing controls and safety rules
ARCControlPanel:
Type: AWS::Route53RecoveryControl::ControlPanel
Properties:
ClusterArn: !GetAtt ARCCluster.ClusterArn
Name: !Sub "${Environment}-control-panel"
# Routing Control - Primary Region (us-east-1)
RoutingControlUSEast1:
Type: AWS::Route53RecoveryControl::RoutingControl
Properties:
ClusterArn: !GetAtt ARCCluster.ClusterArn
ControlPanelArn: !GetAtt ARCControlPanel.ControlPanelArn
Name: !Sub "${Environment}-routing-control-use1"
# Routing Control - Secondary Region (us-west-2)
RoutingControlUSWest2:
Type: AWS::Route53RecoveryControl::RoutingControl
Properties:
ClusterArn: !GetAtt ARCCluster.ClusterArn
ControlPanelArn: !GetAtt ARCControlPanel.ControlPanelArn
Name: !Sub "${Environment}-routing-control-usw2"
# Safety Rule - ATLEAST 1 of 2 routing controls must stay ON
# Prevents an operator from disabling both Regions simultaneously under pressure
MinimumActiveRegionRule:
Type: AWS::Route53RecoveryControl::SafetyRule
Properties:
ControlPanelArn: !GetAtt ARCControlPanel.ControlPanelArn
Name: !Sub "${Environment}-minimum-active-region"
RuleConfig:
Type: ATLEAST
Threshold: 1
Inverted: false
AssertionRule:
AssertedControls:
- !GetAtt RoutingControlUSEast1.RoutingControlArn
- !GetAtt RoutingControlUSWest2.RoutingControlArn
WaitPeriodMs: 5000
Outputs:
ClusterArn:
Value: !GetAtt ARCCluster.ClusterArn
Export:
Name: !Sub "${Environment}-arc-cluster-arn"
ControlPanelArn:
Value: !GetAtt ARCControlPanel.ControlPanelArn
Export:
Name: !Sub "${Environment}-arc-control-panel-arn"
RoutingControlUSEast1Arn:
Value: !GetAtt RoutingControlUSEast1.RoutingControlArn
Export:
Name: !Sub "${Environment}-routing-control-use1-arn"
RoutingControlUSWest2Arn:
Value: !GetAtt RoutingControlUSWest2.RoutingControlArn
Export:
Name: !Sub "${Environment}-routing-control-usw2-arn"The SafetyRule is one of the most important parts of the design. During an incident, people move quickly. The ATLEAST rule with a threshold of one means you cannot turn off both routing controls at the same time. This can be helpful during high-pressure situations to avoid mistakes.
Application-specific stacks generated by the migrator export their routing control ARNs and import them into the health check and Route 53 configurations in separate stacks. That keeps this foundation stack stable while applications are onboarded and offboarded over time.
Lessons That Held Across Every Implementation
A few things have proved consistent across every implementation:
RTO and RPO targets drive every architecture decision. ARC will not improve or replace an architecture that is not designed for regional failover. Active/active and active/passive have very different cost and complexity profiles. Data replication strategy depends on RPO and automation scope depends on RTO. Define the targets first, then use that to guide the architecture. Without those targets, every architecture turns into guesswork.
Separate the routing layer from the application layer. Putting ARC routing controls and health check logic in dedicated stacks separate from individual application deployments means the SRE team can adjust routing without touching an application release. That decoupling is important operationally. It becomes essential when an incident occurs and the SRE team needs to act without waiting for an application team to be available.
A failover plan does not become real until someone owns it. The golden path modules and the GenAI-generated templates are starting points. Practicing failovers and validating is key. The goal should be to move from zero tested failovers to a quarterly game day. That cadence is what makes the RTO number credible and provable at the end of the day.
IaC is not optional for compliance-driven DR. Version-controlled infrastructure definitions for the ARC cluster, routing controls, health checks, and Region Switch plans are what make a DR posture auditable. Version-controlled Terraform modules give auditors the change lineage they require.
Summary
An RTO of 12 hours or more is not just an engineering problem in a regulated industry; it is a compliance risk that grows every time a new workload gets added without a tested failover path. Amazon ARC Region Switch gives you a structured way to address that risk: routing controls, layered health checks, and executable Region Switch plans that turn failover from an improvised process into a practiced one. The GenAI-powered migrator we built on top of AWS Bedrock cuts the onboarding work significantly, but the human review step is just as important as the automation. The generated templates are a starting point but the engineers ultimately shape the outcome. This makes it possible to roll this pattern out across a large application portfolio without it becoming a multi-year effort.
References and Additional Resources
- Amazon Application Recovery Controller Documentation: https://docs.aws.amazon.com/r53recovery/latest/dg/what-is-route53-recovery.html
- ARC Region Switch Getting Started: https://docs.aws.amazon.com/r53recovery/latest/dg/getting-started-regionswitch.html
About the Author
Justin Guse, Solution Partner
Justin is a Solution Partner at Vertical Relevance, specializing in AWS infrastructure, DevOps, and platform automation. He works directly with enterprise clients on cloud migration and modernization initiatives, architecting cloud-native solutions built for security, reliability, and scale – with a focus on translating emerging AWS services into production-ready patterns that reduce risk and accelerate delivery.