

Overview
Hosting workloads in the cloud can simplify hardware procurement and maintenance, but it doesn’t protect against failures in applications and infrastructure. Many site reliability practices focus on designing highly available architectures, creating resiliency tests, and automating failover for specific components, but these precautions do not replace the need for people and processes to respond effectively during a system failure. While we highly recommend incorporating these practices to improve uptime and reduce the impact of incidents, it is important to acknowledge that even the most robust architectures will fail eventually.
When failures occur, it is imperative that the people that must respond are prepared and the processes that are followed have been tested. Unfortunately, despite investing in resilient architecture designs and complex observability solutions, they fail to create a gameday strategy that prepares the people and processes necessary to respond to incidents. At best, this can lead to prolonged outages and unhappy users, and at worst it can result in financial and reputational repercussions.
Traditionally, to address the gameday component of reliability, organizations either point to vast libraries of technical documentation or tests they have performed to induce failures (e.g. chaos testing or performing ad-hoc outage simulations in lower environments). Although these answer important questions, they are not sufficient on their own. These gameday approaches leave the people, documentation, and processes untested which can lead to confusion and delays when real outages occur.
In this solution, we will be breaking down the steps required to perform a successful gameday by testing the people, processes, and technology involved. By executing gamedays, teams can ensure they’re properly documenting system knowledge, testing their procedures, and evaluating their processes in a targeted, controlled environment. Organizations will be able to apply these concepts to all types of failures ranging from isolated components with minimal impact, to expansive systems with multiple failures.
Prescriptive Guidance
Based on the nature of the target systems and organization structure, gamedays will vary from one organization to another. However, the concepts we will discuss can be applied at any organization.
Before we go through an example of a real gameday, it is important to understand the scope for the purposes of the gameday foundations. We will be focusing on the people who will respond to incidents to ensure they are prepared to make the correct decisions under pressure. This preparation includes pressure testing their ability to use the relevant documentation, processes, and tools during an incident. The primary purpose of a gameday is to identify and resolve shortcomings in the way people respond when system failures occur.
Finally, gamedays are only one piece of the larger SRE approach. To ensure that an organization’s systems are reliable it is critical to address all the domains of SRE. For more information on the SRE domains please see Vertical Relevance’s other SRE solutions below.
- Monitoring Foundations and Monitoring Best Practice Guide
- Resilience Testing Foundations
- Performance Testing Foundations
Definitions
- Gameday – Set of carefully curated activities that consist of inducing failure on system(s), testing the people, processes, and technology required to resolve the incident, and identifying areas for improvement to ensure the people involved can respond as effectively as possible in the case of a real incident
- Umpire – The person that is responsible for planning, supervising, and following up on the findings of the gameday
- Tribal Knowledge – Undocumented knowledge of a system only exists only within a single person’s head or has been socialized verbally
- Transitive Failure – System failure that is caused by external component(s) that the system depends upon
- Failure Injection– Intentionally causing a system to produce errors, crash, or otherwise operate improperly. A good example for creating automated failure would be to use Vertical Relevance’s Experiment Broker Module provides an in depth look into failure injection at the enterprise level
Design Principles/Best Practices
While it is impossible to cover all design principles and best practices within the gameday space, below are some of the most critical considerations when executing a gameday.
Prioritize people and scenarios
During gameday activities, Vertical Relevance recommends focusing on areas in which humans are the decision makers. Since the goal of these activities are to identify and resolve issues related to people and processes, you should ensure that is the focus. At different parts of the activity the participants will likely end up interacting with SRE tools and automation (e.g., observability tools, components with automated failover, etc.) but you must keep the focus on people’s ability to use the tools, not the tools themselves. For instance, a common tool-related takeaway is that it is not documented in such a way that the team can operate it in the event of an incident.
If a tool or automation is lacking functionality or fails, it is appropriate to make note, but you should avoid spending time and energy to resolve these issues as part of the gameday. Rather, tools and automation should have their own testing processes as part of their implementation process.
Designate and empower an umpire
The outcome of the gameday starts and ends with the umpire, so selecting an appropriate umpire and instilling a sense of responsibility in them should be a priority. The umpire is responsible for defining the scenario, identifying key takeaways as the team works through the incident, and conducting a debriefing session to cover lessons learned and next steps.
As such, the umpire should be a subject-matter expert on the systems that are being tested (e.g., product owner, senior architect, etc.) so they can effectively target the various components and points of failure of the solution. While designing the activity, the umpire must ensure that the failure injections are isolated to the systems being tested and will not have negative effects on systems outside the scope of the gameday activities.
Create a detailed scenario definition
Since each gameday is intended to target a specific set of people, processes, and tools related to a system, creating a verbose scenario ahead of time is critical. At the very least, Vertical Relevance recommends including the following details in the scenario definition before the gameday begins.
- What are the roles of the personnel who will be responding to the incident?
- What processes are intended to be leveraged as part of the activity?
- What tools and automation are intended to be leveraged as part of this activity?
- What is the acceptance criteria for remediating the failures and concluding the activity?
- What is the acceptable level of risk in the environment and what conditions should indicate the activity needs to be stopped to avoid exceeding the risk threshold?
- Based on SLA’s and other requirements, what is the expected resolution window and if available, what are the target timelines for other milestones in the activity?
Learning from the gameday
At each step of the gameday, from planning to debriefing, learning, and improving should always be the focus. During the execution of the gameday the teams involved should not be discouraged when they do not know how to perform a task, or activities do not go as planned. The only expectation is that teams respond as if it was a real incident and do their best with the knowledge, documentation, and processes that they have.
With this being said, the debriefing stage of the gameday is the most critical part of the process because it is when the umpire and teams involved have the opportunity to identify the gaps and work to correct them so they do not occur during a real incident. Although the term gameday implies that it is a single day event, debriefing and addressing gaps can span multiple days. It is the umpire’s responsibility to make sure that all gaps are tracked and sufficiently addressed before the gameday is considered done.
Performing a Gameday
Our Scenario
Throughout this solution, we will showcase an example for running a Gameday. We will be following a team at VerticalBroker as they prepare for and run a Gameday. VerticalBroker is an example trading company that has thousands of applications used by people around the globe, and a widely distributed system. This team is responsible for an application which provides critical calculations as part of a larger reporting system. This application is hosted in an EKS cluster along with other applications and has a shared dependency on an RDS cluster with other applications.
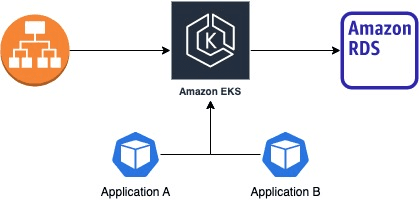
Figure-01
Gameday Prerequisites
Before running the gameday, there are a few prerequisites that must be satisfied to ensure that the activities are able to effectively target the people’s responses, rather than identify issues that should be handled outside of the gameday. When primary outcomes from a gameday should have been in place as part of the prerequisites, it detracts from the value of the gameday. These findings should have been addressed before the gameday began and prevent us from sufficiently evaluating the people and processes as part of the gameday. When prerequisites are not met, it is best to postpone the gameday until they are addressed.
Now let’s look at each prerequisite and how the VerticalBroker team confirmed that each one is addressed.
Knowledge of the Target Systems
Any given component of the systems being tested must have a corresponding gameday participant with deep understanding of the component and permissions to access and operate it. It is acceptable for one team member to be the expert on several components. If any components do not have an expert available on the day of the gameday, the activity should be postponed because it will likely result in a blocker at the unassigned component and produce less effective findings for the subsequent components.
Some reasons that components can be unassigned are if the expert is out of office or the teammate that built and maintained the component left the team. If the expert is out of the office, the gameday should be postponed until their return. However, if the original owner of the component has left the team and there is no one with deep knowledge of it, a new owner must be identified, and they must perform a review of the component and documentation. Once they are comfortable operating the component, it is appropriate to move forward with the gameday.
Observability Capabilities
Before starting a gameday simulation, it’s crucial to have a solid observability strategy in place. This should encompass not only the use of monitoring tools that collect logs in an organized way, but also teams that are equipped with the knowledge of how to effectively use the logs of the components they work on. Without sufficient observability capabilities, the team may face difficulties in accurately pinpointing the root cause of incidents and identifying more subtle issues such as false positives. In such scenarios, the only outcome from the gameday simulation would be the realization of the need for implementing and communicating effective observability capabilities.
VerticalBroker met this prerequisite because they implemented a multi-faceted observability scheme that included the following.
- Metrics and logs stored in Cloudwatch at the account level and aggregated into the organization’s log archive account
- Critical metrics shared via dashboards and an external APM provider
- Cloudwatch Alarms which send event data to SNS queues that alert relevant stakeholders when critical thresholds are not being met
Fault Tolerance Mechanisms
When incidents occur, there are often fault tolerant components and automated responses that are kicked off upon failure. A simple example of this is a cluster of instances spread across availability zones configured such that when one goes offline, it is replaced by a new instance and the new instance is configured using an AWS SSM document. As part of this gameday prerequisite, we expect this automated response to already be tested as part of the organization’s resiliency testing activities, so it does not fail during the gameday.
At VerticalBroker, there are several SSM documents that automate instance configuration as part of self-healing and these features have been resiliency tested as part of the release process. Additionally, they have some miscellaneous automation scripts that assist teams while responding to incidents (e.g., tools that automatically retrieve current entries from upstream databases for troubleshooting purposes) and these scripts have all been tested and documented.
Preparing for the Gameday
Prior to performing a gameday, there are several activities to be completed to design, plan, and set up guardrails for the gameday. Once an umpire is selected, the remaining preparation activities are completed are the responsibility of the umpire.
Select an Umpire
The first step of preparation is selecting an umpire. This individual must have a deep knowledge of the system(s) to be evaluated in the Gameday, a strong understanding of any dependencies the system may have, and familiarity with past incidents or outages that the system(s) have been involved in. The umpire is responsible for conducting preparation activities, injecting failure, overseeing the gameday, and synthesizing the takeaways.
The VerticalBroker team is currently on their third gameday for systems they manage, and they rotate umpires each time to vary the activity and team member responsibilities. This time around, a database expert is the umpire, and the activity is intended to focus heavily on the RDS components.
Identify and Prioritize Scenario
When selecting a scenario, the most basic consideration for the umpire is that it meets the following conditions:
- Human action is required – If no human action is required, this scenario should have been addressed as part of the testing of the tool/automation
- Predictable Failure Injection – The failure injection required by the scenario must yield safe, repeatable results so the component and/or system fails as planned. If the failure injection is not considered safe for the environment, the umpire must either identify a safe environment to inject the failure or revise the gameday scenario so that it is safe
Once the umpire has identified a few potential scenarios, it is time to prioritize them accordingly. The most straightforward way to prioritize is by assigning each potential scenario a ranking based on impact and reproducibility. Once each of these values have been assigned to each, you can use the following matrix to prioritize your scenarios.
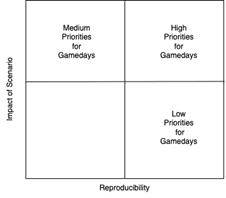
Figure-02
At VerticalBroker, one database error that does not have automated response and can be injected consistently is a new feature that uses an index that is not available. Given the rapid growth of new features being introduced, this situation is very likely, and the team has documentation on troubleshooting and remediating database issues.
Define Scenario Details
With your high-level scenario(s) selected based on priority, you can now fill in the details. While there is no perfect scenario, we recommend leveraging different combinations of the following scenario and failure classifications.
Scenario Classifications
- Quantity of Teams Involved – Targeting a scenario that involves a single team provides a more focused evaluation of the team’s knowledge of available tooling and documentation, as opposed to relying on information from other teams. Conversely, a scenario that involves multiple teams enables testing of scenarios such as escalations, handoffs, or decision points that can have a significant impact on the system. This can reveal areas where clear decisions are lacking or provide a chance to practice coordination between teams, which is critical in real-life situations.
- Degree of Simulation – Ideally, every gameday would be able to be fully simulated and the team would have no access to the environment throughout the activity. This has several benefits including requiring participants to rely on their knowledge and documentation (rather than being able to guess and check when troubleshooting components) and minimizing the potential risk of inducing failure on the system. However, it is not always possible to implement a fully simulated gameday since there is nuance involved in the processes to remediate incidents. Thus, most gamedays are conducted live in a non-production environment and rely on partial simulation. An example of a partial simulation would be that after injecting the failure, the umpire performed one of the remediation tasks, and expected the team to attempt to complete the task, then confidently identify that it had already been completed. This demonstrates confidence in documentation and knowledge of how the incident should be responded to.
Common Failure Types
- False Positive – This type of failure can be designed by introducing a failure that seems to be caused by troublesome log data and/or system behavior despite not being related to it. This can help identify where the team is prone to make hasty decisions without performing a full analysis.
- Cascading – This type of gameday is often a multi-team scenario that focuses on a failure point that triggers a series of subsequent failures. Ideally, each of these potential failure points should be eliminated as part of the activity. This failure type is less common but provides valuable insights into decision points that cannot be uncovered by other scenarios.
- Infrastructure Focused – These types of failures pertain to incidents related to failing infrastructure including but not limited to routing black holes, firewall issues, and regional outages.
- Application Focused – This type of failure focuses on failures within application code such as packages that fail during building or breaking changes that were included in a recent version update. Any incident that requires fixing broken application code can be classified as an application focused failure.
The VerticalBroker team has chosen to conduct a single team gameday in a non-production environment for the selected scenario. The focus will be on application failure, specifically by removing a critical table index used by the application.
Define Failure Injection Guidelines
Typically, any gameday that is not fully simulated requires at least some degree of failure injection. In these cases, it is important to explicitly document the intended failure injection procedures ahead of time as well as the steps that will be required to restore the environment to its original state in case the team is unable to do so as part of the activity.
When creating failure injection guidelines, it’s crucial to be mindful of the amount of failure injection you introduce. Limiting failure injection to the essential minimum allows you to focus the scenario and produce more precise results. By avoiding excessive or unnecessary failure injection, the gameday will remain focused and provide more accurate insights.
At VerticalBroker, the umpire has written a script that simulates application load to the table and then removes an in-use index from the table. This script has been tested to consistently produce the same errors that are resolved by re-creating the missing index. Since this activity is taking place in the non-production environment and the appropriate stakeholders have been informed of the activity, no other teams will be adversely affected.
Prepare Halt conditions
Any time failure is being injected into the system, the umpire must prepare halt conditions. Halt conditions are intended to serve as boundaries for the exercise such that if they are reached, the activity must be steered to maintain acceptable levels of failure on the systems. Conditions of a halting the event must consider the impact that the failures would be causing in production since this activity is meant to emulate the actions taken if the incident were to happen in production.
There are certain situations when halt conditions become necessary to prevent further issues. Two common examples include:
- When failure spreads to unplanned systems, halting the activity can prevent further damage or disruption.
- When the team reaches a point where they need to escalate the issue to a different team that is not involved in the current activity, halting the activity can ensure a smooth handover and prevent confusion or miscommunication.
Since the VerticalBroker umpire expects that the issue will trigger alerts within five minutes of failure injection and that the team is expected to escalate if it cannot be remediated in thirty minutes, the halt condition is set to 30 minutes after the initial alarms are triggered.
Incorporating Unfamiliar Teams (Optional)
For more mature environments and teams that have already performed many gamedays, the umpire has the choice to bring in individuals who are not familiar with the systems that are the subject of the gameday. With limited prior knowledge of the systems, the individuals running the gameday are forced to rely solely on the processes, documentation, and tools at hand. This results in a more thorough and realistic evaluation of the incident response capabilities, highlighting any areas that may require improvement. In these cases, the team members responsible for the systems should still be available throughout the gameday in case halt conditions are reached and the system needs to be restored to its original state immediately.
Even though the VerticalBroker team has performed multiple gamedays on this system, they have not tested this component specifically and are therefore not candidates to leverage the strategy of incorporating unfamiliar teams.
Executing the Gameday
With the scenario, failure injection, and halt conditions defined, when the day of the activity arrives, the actions taken by the umpire should be almost entirely planned. Once the team is ready, the umpire will validate that the system is healthy and start the gameday by initiating the failure injection. It is important for the umpire to record the exact time that the failure was injected so he can discern what logs and alerts were already existing prior to the gameday.
Once the failure is injected and the team is working to find the root cause and determine the path to remediation, the umpire should have visibility into all communications between the team including chats and meeting bridges. The umpire is only allowed to participate as a silent observer and cannot provide any support or guidance in the activity unless halt conditions are reached. Throughout the entire activity, the umpire is responsible for taking notes on the following:
- Documentation, processes, and tooling used
- Dependent systems interacted with
- Issues encountered and questions asked amongst teammates
- Manual actions
- Opportunities to automate
The activity will conclude when the team has either remediated the failure or halt conditions have been met. At this point the umpire should ensure that the environment is returned to the same state as before the Gameday began, that all failure injection has been disabled, and that any transient failures in dependencies have recovered. Any unexpected efforts in cleaning up from the Gameday should be tracked as additional findings. Once the system(s) have been restored to their original state, the umpire should briefly discuss their notes with the team, gather additional notes from the team, and schedule follow up debriefing sessions.
When the day of the activity arrived at VerticalBroker, the umpire began by validating the health of the system. When the team was ready, the umpire recorded the time and introduced failure into the system by running the script to induce load onto the table and remove a working index. For the remainder of the activity, the umpire observed the team and took notes by following along on the call and in chat. For the first twenty minutes, the team struggled to navigate the documentation, but once they found the section pertaining to the error, they were able to remediate the problem in minutes – narrowly avoiding the halt condition. After congratulating the team on a successful gameday activity, the umpire and team briefly exchanged notes on the activity and the umpire scheduled an in-depth debrief for the following day.
Addressing Gameday Findings
Once the gameday activities reveal the shortcomings of how your people, processes, and technology respond to incidents, it is imperative to address these items so they do not occur during a similar production incident. The follow-up structure on the gameday should mirror the organization’s incident post-mortems. As part of this, the umpire and team should use the umpire’s notes to walk through all the events of the gameday from failure injection through the system being restored to its original state. At each step, the group should discuss and evaluate findings with the team and how to remediate them.
Each actionable finding that is identified should be assigned to a teammate to remediate by either studying documentation to improve their understanding, updating gaps in documentation, revising processes, or updating technology that was used. Additionally, if the group identified any unrelated bugs or procedural gaps, they should be assigned to a team member, remediated, and tested.
Finally, the team should address the findings with the same urgency as if they were identified as part of a production incident. To ensure that all the gaps have been remediated, the gameday activity should not be officially marked as done until all the findings have been addressed and approved by the umpire. At this point, we encourage teams to share their findings with other teams in the organization to provide lessons learned and help give other teams inspiration for their future gamedays.
At VerticalBroker, gameday was very short and precisely targeted, so there were very few actionable findings. The findings that were tracked were delays while navigating documentation and a bug in a component that was not intended to be tested as part of the gameday. Two team members were assigned the action items to improve specific portions of the documentation and fix the bug. Once these items were complete, the umpire marked the findings as addressed, marked the gameday complete, and shared the findings with the teams that manage adjacent, dependent systems.
Blueprint
This blueprint comprises of a pipeline to upload SSM Documents to AWS, a set of SSM documents for testing purposes, as well as a lambda to execute SSM Automation documents.
- CDK Pipeline – The pipeline is created through CDK, which will allow the user to easily deploy this pipeline in whichever account necessary.
- Lambda Execution – The second CDK Application concerns a lambda which is used to execute the documents uploaded via the pipeline section. In order to execute the documents via lambda, you must deploy the lambda via CDK.
Benefits
- Confidence in the people, processes, and technology required to swiftly respond to an incident
- Identify and remediate gaps in incident response processes before incidents occur
- Guidelines for creating gameday scenarios to replicate the most critical incidents that can occur in an organization
- Team members are prepared and confident when they must respond to production system failures
- Positive incident response habits are formed, and inefficiencies are identified and resolved
End Result
In this solution, we discussed the significance of ensuring operational resiliency through gameday execution. We demonstrated how to set up gamedays and how they can supplement your efforts to ensure operational resilience. After teams start executing Gamedays regularly, they counteract the natural tendency to lose sight of the human part of incident response. As the umpire has been selected and prepared the Gameday they have simultaneously limited the scope. In running the Gameday the team has faced the scenario presented and found any gaps in documentation, process, or knowledge. By following up on these findings the team can learn retrospectively from the Gameday and be prepared for any incidents that might be related to the scenario.